https://szkolazpieklarodem.pl/
Znakowanie części mowy (Part-of-speech POS) to proces, podczas którego czytasz jakiś tekst i przypisujesz części mowy do każdego słowa lub symbolu, takiego jak rzeczownik, czasownik, przymiotnik itp. Znakowanie POS staje się niezwykle ważne, gdy chcesz zidentyfikować jakiś podmiot w danym zdaniu. Pierwszym krokiem jest wykonanie tagowania POS i sprawdzenie, co zawiera nasz tekst. Zajmijmy się kilkoma przykładami prawdziwego tagowania POS.
Przykład 1:
nlp = spacy.load(‘en’) #Loads the spacy en model into a python object
doc = nlp(u’I am learning how to build chatbots’) #Creates a doc object
for token in doc:
print(token.text, token.pos_) #prints the text and POS
Dane wyjściowe:
(‘I’, ‘PRON’)
(‘am’, ‘VERB’)
(‘learning’, ‘VERB’)
(‘how’, ‘ADV’)
(‘to’, ‘PART’)
(‘build’, ‘VERB’)
(‘chatbots’, ‘NOUN’)
Przykład 2:
doc = nlp(u’I am going to London next week for a meeting.’)
for token in doc:
print(token.text, token.pos_)
Dane wyjściowe:
(‘I’, ‘PRON’)
(‘am’, ‘VERB’)
(‘going’, ‘VERB’)
(‘to’, ‘ADP’)
(‘London’, ‘PROPN’)
(‘next’, ‘ADJ’)
(‘week’, ‘NOUN’)
(‘for’, ‘ADP’)
(‘a’, ‘DET’)
(‘meeting’, ‘NOUN’)
(‘.’, ‘PUNCT’)
Jak widzimy, drukując tokeny ze zwróconego obiektu Doc z metody nlp, która jest kontenerem umożliwiającym dostęp do adnotacji, otrzymujemy POS otagowany każdym ze słów w zdaniu. Te znaczniki to właściwości należące do słowa, które określają, że słowo jest użyte w poprawnym gramatycznie zdaniu. Możemy używać tych znaczników jako funkcji słów w filtrowaniu informacji itp. spróbujmy wziąć inny przykład, w którym próbujemy zbadać różne atrybuty tokena pochodzącego z obiektu Doc.
Przykład 3:
doc = nlp(u’Google release “Move Mirror” AI experiment that matches your
pose from 80,000 images’)
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
Dane wyjściowe:
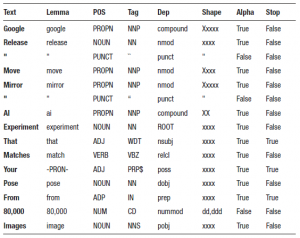
Przykład 4:
doc = nlp(u’I am learning how to build chatbots’)
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
Dane wyjściowe:
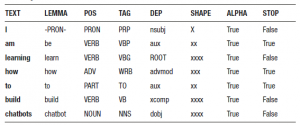
Zapoznaj się z poniższą tabelą, aby poznać znaczenie każdego atrybutu, który wydrukowaliśmy w kodzie.
TEXT: Rzeczywisty tekst lub przetwarzane słowo
LEMMA: Rdzeń przetwarzanego słowa
POS: Część mowy słowa
TAG: wyrażają część mowy (np. CZASOWNIK) i pewną ilość informacji morfologicznych (np., że czasownik jest w czasie przeszłym).
DEP: Zależność syntaktyczna (tj. relacja między tokenami)
SHAPE : kształt słowa (np. wielkość liter, znaki interpunkcyjne, format cyfr)
ALPHA: Czy token jest znakiem alfa?
Stop: Czy słowo jest słowem stop, czy częścią listy stop?
Możesz zapoznać się z poniższą tabelą, aby zrozumieć, co oznaczają poszczególne wartości atrybutów POS obiektu tokena. Ta lista zawiera szczegółowy opis znaczników części mowy przypisanych przez modele spaCy.
POZ: OPIS: PRZYKŁADY
ADJ: przymiotnik: duży, stary, zielony, niezrozumiały, pierwszy
ADP: przyimek: w, do, podczas
ADV: przysłówek: bardzo, jutro, w dół, gdzie, tam
AUX: pomocniczy: jest, zrobił (zrobił), będzie (zrobi), powinien (zrobić)
CONJ: spójnik: i, lub, ale
CCONJ: spójnik koordynujący: i, lub, ale
DET: wyznacznik: a, an, the
INTJ: wykrzyknik: psst, ouch, brawo, cześć
NOUN.: rzeczownik: dziewczyna, kot, drzewo, powietrze, piękno
NUM: cyfra: 1, 2017, jeden, siedemdziesiąt siedem, IV, MMXIV
PART: cząstka: „s, nie,
PRON: zaimek: ja, ty, on, ona, ja, oni sami, ktoś
PROPN: rzeczownik własny: Mary, John, London, NATO, HBO
PUNCT: interpunkcja: ., (, ), ?
SCONJ: spójnik podrzędny: jeśli, podczas gdy, to
SYM: symbol: $, %, §, ©, +, −, ×, ÷, =, :), ½
VERB: czasownik: biegać, biegać, biegać, jeść, jeść, jeść
X: inne: sfpksdpsxmsa
SPACE: przestrzeń
Dlaczego więc tagowanie POS jest potrzebne w przypadku chatbotów? Odpowiedź: aby zmniejszyć złożoność zrozumienia tekstu, którego nie można wytrenować lub który jest przeszkolony z mniejszą pewnością. Dzięki tagowaniu POS możemy zidentyfikować części wprowadzanego tekstu i dopasować ciągi tylko dla tych części. Na przykład, jeśli chcesz sprawdzić, czy w zdaniu istnieje lokalizacja, znacznik POS oznaczy słowo lokalizacji jako RZECZOWNIK, dzięki czemu będziesz mógł pobrać wszystkie RZECZOWNIKI z listy oznaczonych i sprawdzić, czy jest to jedna z lokalizacji z wstępnie ustawionej listy albo nie.

