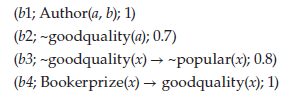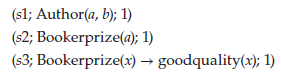Jesteśmy teraz zainteresowani skończonym zestawem agentów A, tym, w jaki sposób agenci ufają sobie nawzajem i używają tej reprezentacji w logice. Jeśli Trusts (Agi, Agj), gdzie Agi, Agj ∈ A, to Agi ufa Agj. Nie jest to relacja symetryczna, więc niekoniecznie jest tak, że Trusts (Agi, Agj) ⇒ Trusts (Agj, Agi). W pracy nad zaufaniem zwykle rozważa się wnioskowanie o zaufaniu przy założeniu, że relacje zaufania są przechodnie. Proces wnioskowania jest tym, co nazywamy „bezpośrednią propagacją”. Innym rodzajem relacji zaufania jest zaufanie pośrednie. Ten typ zaufania można obliczyć przy użyciu wartości zaufania agenta zebranej od sąsiadów lub innych podobnych agentów. Naszym celem jest pokazanie wykorzystania logiki i argumentacji do propagowania wartości zaufania między agentami w RS. Innymi słowy, chcemy podejścia opartego na argumentacji, którego agent może użyć, aby określić, że ma powód, by ufać innemu agentowi, a następnie połączyć to zaufanie z inną posiadaną wiedzą, aby podejmować decyzje dotyczące zaleceń. W systemie każdy agent Agi ma BB, czyli jakiś zbiór informacji o świecie, który nazwiemy BBi i jest to wyrażone logicznie. BBi składa się z kilku następujących partycji:
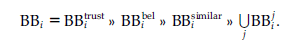
Tutaj zaufanie BBitrust zawiera informacje o stopniu zaufania, jakim Agi darzy innych znanych mu agentów, BBibel to zbiór przekonań lub faktów (w postaci predykatów) Agi na temat świata (który, jak zakładamy, ma pewną miarę wiary ), BBi podobny zawiera miarę podobieństwa Agi do innych czynników (podobieństwo między dwoma agentami jest obliczane przez zastosowanie podobieństwa cosinusowego do ich upodobań i antypatii dla preferencji), a pewne informacje BBij, że Agi jest świadczone przez każdego z sąsiadów Agj. Elementy BBi to trojaczki, jak opisano w pracy Parsonsa Każdy element ma postać: (id_typu; dane; wartość). Pierwszy parametr type_id służy do odwoływania się do elementu określonego typu BBi, drugi parametr to formuła, a trzeci to ilościowa miara zaufania / przekonania / podobieństwa w zależności od tego, do którego podziału BBi element się odwołuje. . Wszystkie argumenty mają postać: (wniosek; podstawy; reguły; wartość). Wniosek wyprowadza się z podstaw za pomocą reguł wnioskowania, czyli reguł (jak określono poniżej), a wniosek wyprowadza się na podstawie stopnia mającego wartość.

Reguła Argtrust mówi, że jeśli jakiś agent Agi ma tryplet: (t1; trusts (x, y); 0,4) w swoim BBítrust, to może skonstruować argument dla trustów (x, y), gdzie podstawami są t1, stopień zaufania wynosi 0,4, co oznacza, że do jego wyprowadzenia użyto reguły Argtrust.
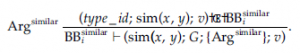
Podobnie reguła Argsimilar mówi, że jeśli jakiś agent Agi ma trójkę: (s1; sim (x, y); 0,9) w swoim BBisimilar i wtedy może skonstruować argument dla sim (x, y), w którym podstawy są podane przez zbiór G (połączy wszystkie fakty użyte do określenia podobieństwa), stopień podobieństwa wynosi 0,9 i który rejestruje, że reguła Argsimilar został użyty w jego wyprowadzeniu.

gdzie:
n = 1 do p
p oznacza liczbę agentów bezpośrednio znanych x (tj. sąsiadów x)
Licznik w powyższym wyrażeniu można powtórzyć co najwyżej p tyle razy, ponieważ p określa maksymalną liczbę agentów znanych x, którzy również znają z. Reguła Arggdt obejmuje bezpośrednie propagowanie przez grupę wartości zaufania dla z uzyskanych z grupy sąsiadów x. Mówi się, że jeśli możemy wykazać, że zaufanie (x, yn) zachowuje się na poziomie vn i możemy pokazać, że zaufanie (yn, z) ma stopień wn dla pewnego agenta yn, to możemy zawrzeć zaufanie (x, z) ze stopniem vn ≈ agg(trust) wn, a wniosek opiera się na połączeniu informacji, które wspierały przesłanki, i jest obliczany przy użyciu wszystkich reguł używanych przez obie przesłanki. Tutaj vn ≈ agg(trust)wn jest interpretowane jako agregacja różnych wartości zaufania (połączonych indywidualnie przez operację ≈trust) uzyskanych z różnych źródeł zaufanych przez agenta i. Dlatego rozszerzamy połączenie w następujący sposób:

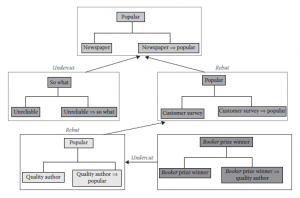
Powodem, dla którego jesteśmy zainteresowani wykorzystaniem argumentacji do obsługi zaufania, jest to, że chcemy zapisać, w formie argumentu dla jakiejś propozycji, powody, dla których należy w to wierzyć. Ponieważ informacja o źródle pewnych danych i zaufanie, jakim agent darzy źródło, są istotne, należy je zapisać w argumencie. Jest to łatwiejsze do osiągnięcia, jeśli zakodujemy dane o tym, kto ufa komu w logice. Do tej pory wyjaśniliśmy, w jaki sposób agent Agi może wnioskować o wiarygodności innych agentów. Powodem tego jest to, że Agi może wykorzystać informacje o zaufaniu, aby zdecydować, jak wykorzystać informacje otrzymane od tych agentów. Rozważmy teraz następujący zestaw reguł wnioskowania o przekonaniach:

Wszystkie te informacje o zaufaniu, to znaczy reguły z równań, mogą być następnie użyte, razem z powyższymi regułami podanymi w dalszych równaniach, do skonstruowania argumentów, które łączą zaufanie i przekonania agentów. Reguła Argbelief wyodrębnia argument z pojedynczej informacji, podczas gdy reguły wprowadzające koniunkcję (IC) i modus ponens (MP) są typowymi naturalnymi regułami dedukcji. Zasady dotyczące IC i eliminacji implikacji lub MP są uzupełnione kombinacją stopni przekonań i gromadzeniem informacji składających się z danych i reguł dowodowych. Kluczową regułą jest reguła o nazwie Zaufanie. To mówi, że jeśli możliwe jest skonstruowanie argumentu dla α z jakiegoś BBij, wskazującego, że informacja pochodzi od Agj, a Agi ufa Agj i Agi podobnie do Agj, to Agi ma argument za α. Podstawy tego argumentu łączą wszystkie dane, które zostały wykorzystane z BBij, wszystkie informacje o podobieństwie użyte do ustalenia, że Agi jest podobne do Agj oraz wszystkie informacje o zaufaniu użyte do ustalenia, że Agi ufa Agj, oraz zestaw reguł w argumencie zapisz wszystkie wnioski potrzebne do zbudowania tego połączonego argumentu. Wreszcie, przekonanie, które Agi ma w argumentacji, jest wiarą w α, tak jak zostało wyprowadzone z BBij, w połączeniu z podobieństwem i zaufaniem Agi do Agj. W związku z tym zasada ta sankcjonuje wykorzystanie informacji od znajomych agenta, pod warunkiem że stopień wiary w tę informację jest modyfikowany przez podobieństwo agenta i zaufanie do niego. W związku z tym jeden agent może importować informacje od innego agenta tylko wtedy, gdy pierwszy agent może skonstruować argument zaufania, który określa, że powinien ufać drugiemu (drugiemu) agentowi za pomocą reguły zaufania.