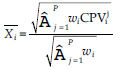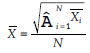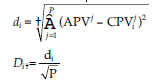SQ jest miarą rzeczywistego systemu elektronicznego systemu informacyjnego, wykorzystując konstrukcje funkcjonalności, niezawodności, użyteczności i wydajności jako wyznacznika ogólnego zadowolenia użytkownika i istotnego predyktora użytkowania systemu. cechy i charakterystyka wydajności e-administracji. Witryna internetowa zwiększająca satysfakcję użytkownika z systemu. Lepszy SQ i lepsza obsługa są ponadto związane z satysfakcją użytkowników
Użyteczność
Użyteczność koncentruje się na kwestiach ludzkich, na tym, jak użytkownicy postrzegali cele projektu, takie jak funkcjonalność, wydajność i niezawodność w Internecie. Na tym poziomie użyteczności ogólne zasady obejmują wsparcie dla zadań użytkownika, szczegóły interfejsu, takie jak projekt menu lub użycie przewodnika po stylach w celu ułatwienia przetrwania w Internecie. Użyteczność jest również połączeniem jakości z prostotą obsługi interfejsu użytkownika, tak aby użytkownicy mogli łatwo i szybko wykonywać zadania, byli w stanie płynnie lub konsekwentnie poruszać się po witrynie internetowej oraz byli w stanie zrozumieć funkcje witryny internetowej po patrzeć na główną stronę główną przez kilka sekund. Dlatego kluczem użyteczności jest nie tylko to, jak dobrze działa witryna internetowa, ale także stopień, w jakim witryna internetowa spełnia potrzeby użytkowników [66]. Większość użytkowników ponownie odwiedza witrynę sieci Web z powodu wysokiej jakości zawartości, częstych aktualizacji, minimalnego czasu pobierania i łatwości użytkowania
Funkcjonalność
Funkcjonalność zapewnia integracyjne i interaktywne funkcje dla wygody użytkownika końcowego. Dobrze funkcjonujące rządowe witryny sieci Web są głównie przeznaczone do wyszukiwania, klasyfikowania i integrowania informacji, które są powiązane z istniejącą witryną sieci Web dla użytkowników. Dobrze funkcjonujące portale zapewniłyby obywatelom dostęp do wszystkich niezbędnych informacji. W związku z tym funkcjonalność można opisać w kategoriach dostosowywania i otwartości. Dostosowywanie portalu internetowego jest wykorzystywane głównie w celu zaspokojenia potrzeb odwiedzających portal. Oznacza to, że funkcjonowanie sieci dostarcza treści, które dają użytkownikom bezpośrednią potrzebę wyszukiwania informacji. Dlatego dostarcza informacji w wyspecjalizowany sposób.
Reakcja na coś
Reakcja jest w rzeczywistości reakcją użytkowników e-administracji. Jest to wartość zorientowana na klienta, która zapewnia usługi, które odpowiadają wartościom i wymaganiom klientów. Szybka i odpowiednia reakcja na żądanie oraz terminowe aktualizacje to elementy, które mają wpływ na szybkość reakcji. Reakcję e-administracji można mierzyć na forach elektronicznych na stronie internetowej i specjalnych formularzach internetowych zawierających komentarze i sugestie. Te komentarze pomogłyby w opracowaniu polityki rządu.
Wydajność
Wydajność jest definiowana jako sprawność systemu w zapewnianiu odpowiedniej wydajności i względnej ilości wykorzystanych zasobów. Charakterystyka wydajności jest powiązana ze współczynnikiem czasu. Z punktu widzenia użytkownika miarą używaną do oceny jakości działania systemu internetowego jest zachowanie czasu. Użytkownicy postrzegają czas odpowiedzi jako czas od momentu kliknięcia łącza i wykonania na nim kliknięcia myszą od momentu pełnego wyświetlenia nowej strony internetowej na ekranie. Nazywa się to stanem ładowania z warunkami przepustowości. Głównym celem wydajności powinien być łatwy dostęp do informacji tekstowych, które są potrzebne, bez konieczności długiego czekania lub marnowania czasu nawet przy niskich warunkach przepustowości, podczas gdy limit czasu przesyłania dla każdej aplikacji internetowej powinien być krótszy niż 30 sekund.
Proponowane ramy
W oparciu o przegląd literatury w badaniu zaproponowano ramy rozwoju zaufania obywateli do usług e-administracji. Konstrukcje tej struktury zostały zaadaptowane na podstawie odpowiednich wcześniejszych badań, takich jak te podane w literaturze. Po dokładnym przeanalizowaniu literatury zaproponowana struktura składa się z pięciu głównych konstrukcji, w tym bezpieczeństwa danych i informacji, IQ, SQ, zaufania do Internetu i zaufania do rządu.
Wnioski
W tym rozdziale zidentyfikowano i zaproponowano relacje między bezpieczeństwem, jakością i zaufaniem obywateli. Proponowany model lub ramy w tym rozdziale są oparte na przeglądzie literatury. Ogólnie rzecz biorąc, sukces organizacji rządowej zależy od bezpieczeństwa i jakości usług administracji elektronicznej świadczonych obywatelom; dlatego zrozumienie konstrukcji, koncepcji i wymiarów usług e-administracji zwiększa zaufanie obywateli. Proponowane ramy zapewniają zrozumienie wymaganych atrybutów bezpieczeństwa i jakości w usługach e-administracji i podkreślają, na co należy zwrócić uwagę wśród dostawców usług e-administracji lub menedżerów, a także pomagają im w poprawie wydajności usług e-administracji