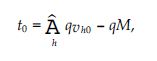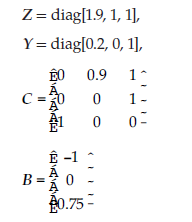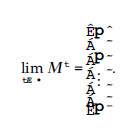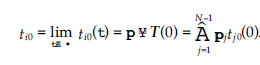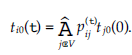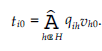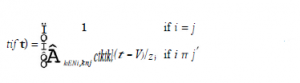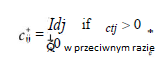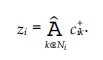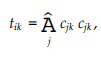W tej sekcji opiszemy liniowe kodowanie sieci , które zapewnia wydajną propagację poświadczeń zaufania i powiązane operacje, które są zdecentralizowane. Kodowanie sieci to nowa dziedzina teorii informacji, której zaproponowano w celu poprawy wykorzystania przepustowości danej topologii sieci. Ahlswede i inni jako pierwsi wprowadzili kodowanie sieciowe. Przedstawmy powierników, którzy są zainteresowani wiarygodnością konkretnego użytkownika zwanego powiernikiem. Poświadczenia zaufania dotyczące powiernika są początkowo przechowywane w rozproszonych węzłach w całej sieci. Węzły te wystawiają poświadczenia zaufania lub pobierają je od innych. Poświadczenia zaufania będą wskazywać tylko jednego powiernika, a wszystkie operacje są stosowane na tych poświadczeniach dotyczących powiernika. Każde poświadczenie zaufania, w postaci dokumentu cyfrowego, ma unikalny identyfikator, który uzyskuje się poprzez zastosowanie funkcji skrótu do dokumentu. W sieciach autonomicznych węzły komunikują się bezpośrednio tylko z niewielkim podzbiorem innych węzłów zwanych sąsiedztwem, a węzły często sprawdzają u swoich sąsiadów nowe poświadczenia. Nowe poświadczenia są przekazywane do węzła, gdy wykryje je w swoim sąsiedztwie. Za każdym razem, gdy węzeł przekazuje dalej poświadczenia zaufania, tworzy liniową kombinację wszystkich poświadczeń, które ma obecnie w pamięci, i połączonych dokumentów, które otrzymał od sąsiadów.
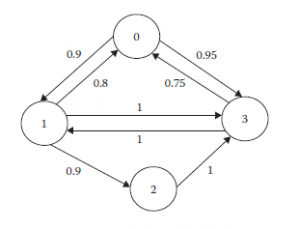
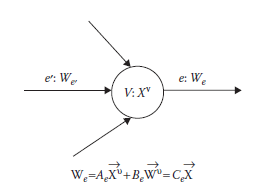
Rozważmy sieć jako graf G = (V, E), gdzie V to zbiór węzłów, a E to zbiór krawędzi. Krawędzie są oznaczone przez e – (v, v’) E, gdzie v = head(e) i v’ = tail(e). Zbiór nadchodzących krawędzi jest oznaczony jako I(v) = {e E: head (e) = v}, a stopień wejściowy v to deg1(v) = |I (v)|. Podobnie zbiór wychodzących krawędzi jest oznaczony jako O(v) = {e E: tail (e) = v}, a stopień wyjściowy v to deg0 (v) = |O(v)|. Oznaczmy przez Xvl ,l= 1, … , h jedno z h poświadczeń, które przechowuje węzeł v, a przez Wve’, połączony dokument przesłany do v przez krawędź e’. Rozważ jedną wychodzącą krawędź v, krawędź e. Połączony dokument przesyłany za pośrednictwem łącza e jest zdefiniowany następująco:
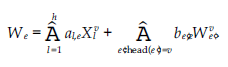
Wszystkie te operacje mają miejsce w skończonym polu Fq. Współczynniki al,e i be’e są wybierane losowo z Fq, a zawartość danych każdego dokumentu zaufania jest reprezentowana przez d elementy z Fq. Wektor współczynnika połączonego dokumentu We jest definiowany jako Ce = [ce,1, ce,2r …, ce,m], gdzie m to całkowita liczba dostępnych poświadczeń zaufania. Zgodnie z równaniem powyzej, współczynnik referencji Xlv to al,e. Załóżmy, że współczynnik referencji Xl’ w połączonym dokumencie Wev wynosi ce’l Wtedy mamy to
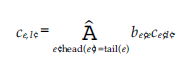
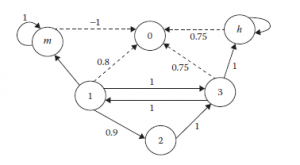
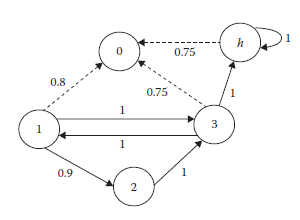
Rysunek przedstawia przepływ dokumentów od krawędzi e’ do węzła v i dalej do krawędzi e
Obserwuje się, że mając m różnych dokumentów zaufania, węzeł może je odzyskać po odebraniu m połączonych dokumentów, dla których powiązane wektory współczynników są od siebie liniowo niezależne. Proces rekonstrukcji jest podobny do rozwiązywania równań liniowych. Schemat oparty na kodowaniu sieci obejmuje tylko interakcje lokalne. Węzły nie muszą być świadome istnienia jakichkolwiek poświadczeń zaufania i ich lokalizacji. Kontaktują się tylko z sąsiadami, aby sprawdzić, czy są nowe poświadczenia lub nowe połączone dokumenty. Jest to zaleta w porównaniu z jakimkolwiek schematem żądanie-odpowiedź, takim jak schemat oparty na Freenet [30]. Schematy odpowiedzi na żądania wymagają tablic routingu. Jeśli topologia sieci zmienia się, gdy nowe węzły wchodzą do sieci lub niektóre węzły się przenoszą, tablice routingu należy natychmiast zaktualizować. Schemat kodowania sieci szybko dostosowuje się do zmian topologii, ponieważ węzły kontaktują się tylko ze swoimi obecnymi sąsiadami. Ponadto schematy żądanie-odpowiedź wymagają, aby węzły znały identyfikatory dokumentów przed wysłaniem żądań, co wymaga globalnej wymiany informacji. Schemat kodowania sieciowego działa bez znajomości identyfikatora dokumentu.