Dostępność poufnych informacji w sieci spowodowała włamanie do Google, czyli proces wykorzystywania zaawansowanych zapytań Google do lokalizowania poufnych informacji w sieci. Oto przykład:
![]()
Spowoduje to wysłanie zapytania do arkuszy kalkulacyjnych (plików .xls) Google for Excel, które mogą zawierać nazwy użytkowników i hasła. Działa, podobnie jak wiele innych 1422 zapytań w Google Hacking Database, repozytorium zapytań wyszukiwania znanych z dostarczania poufnych informacji . Kiedy myślisz o poufnych informacjach, które są dostępne za pośrednictwem publicznie dostępnego interfejsu Google, powinieneś również rozważyć, jakie informacje mogą być pobierane przez wewnętrznych pracowników Google z nieograniczonym dostępem do surowej bazy danych i, prawdopodobnie, możliwością precyzyjnego konstruowania zapytań przy użyciu potężnego standardu branżowego narzędzia, takie jak Structured Query Language (SQL) i wyrażenia regularne. Jak widzieliśmy, nawet zaawansowane zapytania użytkowników Google są nadal dość ograniczone.
Złe boty
W tym miejscu warto zapytać, co mógł zrobić zły bot pokrewny Googlebotowi? Wspomniałem już o wartości Googlebota jako narzędzia rozpoznawczego, ale boty mogą wyrządzać inne, bezpośrednie formy psot. Szereg robotów sieciowych pracujących wspólnie może przeprowadzić rozproszony atak typu „odmowa usługi” (DDoS) na witryny internetowe i inne usługi online, wielokrotnie żądając dokumentów, co ostatecznie przerośnie serwery. Jednak nie uważam tego za realistyczne zagrożenie ze strony dużej firmy internetowej, takiej jak Google, chyba że doznała ona masowego (i mało prawdopodobnego) kompromisu z maszynami kontrolującymi Googlebota. Prawdziwe zagrożenie DDoS pochodzi z botnetu, sieci zagrożone komputery domowe i służbowe. Ze względu na niefortunne nakładanie się terminologii należy zauważyć, że botnet to zupełnie inne zwierzę niż webbot. Botnety powstają, gdy atakujący umieścili złośliwe oprogramowanie na dużej liczbie zaatakowanych maszyn, skutecznie umieszczając każdą maszynę pod kontrolą jednego napastnika, czasami nazywanego armią botów. Botnety składające się nawet z miliona maszyn istnieją i były wykorzystywane w udanych atakach DDoS, ale nie na żądanie dużych firm internetowych. Mając to na uwadze, możliwe są interesujące ataki przy użyciu robotów internetowych. Boty posługują się wieloma protokołami i mogą przeprowadzać ataki na te usługi. Badacze codziennie odkrywają nowe ataki, a boty można zaprogramować tak, aby przeprowadzały je na pojedynczym serwerze, klasie serwerów lub nawet na każdym napotkanym przez bota serwerze. Mało prawdopodobne? Być może szczególnie w przypadku dużych firm internetowych, ale nie jest to niemożliwe. Przypomnij sobie, że roboty internetowe nieustannie trollują w sieci w poszukiwaniu linków do śledzenia, a wiele serwerów internetowych może zostać zaatakowanych za pomocą źle sformułowanych linków. Badacz bezpieczeństwa Michał Zalewski wykorzystał oba te fakty, umieszczając przykładowe złośliwe linki na stronie internetowej odwiedzanej przez roboty internetowe; zobacz poniższą listę.
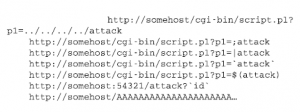
Kilka dni później roboty powróciły i wypróbowały niektóre skażone linki na docelowym hoście. Kluczową ideą jest to, że Zalewski był w stanie nakłonić roboty sieciowe dużych firm internetowych do wykonania ataków wybranych przez siebie na dowolne maszyny. Eksperyment Zalewskiego wskazuje na zupełnie nowy wektor zagrożeń.
Podsumowanie
Googlebot to niestrudzony interfejs użytkownika urządzenia Google do gromadzenia danych. Jego koncepcja jest prosta: Googlebot po prostu automatyzuje proces przeglądania sieci i przekazuje informacje z powrotem do serwerów zaplecza Google. Wzmacnia ogromne ujawnienia, które ludzie ujawniają za pomocą narzędzi internetowych, o informacje, które ludzie umieszczają w publicznie dostępnej sieci. Przy co najmniej 19 miliardach stale zmieniających się stron internetowych i 50 milionach blogów istnieje ogromne morze informacji do trolli. W świecie, w którym bardzo łatwo jest publikować informacje, opublikowanie wrażliwych informacji zajmuje tylko niewielki procent użytkowników informacje, celowo lub przypadkowo, oraz przechwytywania, buforowania i publicznego udostępniania przez Google. Użytkownicy sieci mają wyraźną skłonność do publikowania poufnych informacji. Nawet niewinnie wyglądające informacje będą zawierały unikalne atrybuty (np. Adresy e-mail i ulice, numery telefonów i nazwiska), które mogą łączyć zawartość z profilami użytkowników. Dyski twarde stają się coraz tańsze z dnia na dzień. Zatem po ujawnieniu takich informacji można bezpiecznie założyć, że będą istnieć wiecznie. Jednak nie powinieneś przejmować się tylko tymi plikami; największe zagrożenie może pochodzić z archiwów korporacyjnych w całej sieci. Chociaż niektóre witryny próbują archiwizować migawki z sieci [37], ogromne korporacje, takie jak Google, mogą rutynowo archiwizować znaczną część sieci. Googlebot to najlepszy silnik rozpoznawczy dla Google, ale nie dla użytkowników końcowych. Użytkownicy końcowi uzyskują dostęp do publicznie dostępnej bazy danych zbudowanej za pośrednictwem Googlebota. Tak więc nasz silnik rozpoznawczy jest interfejsem wyszukiwania Google i tym, co Google uważa za publicznie dostępne. Wizyty Googlebota są oczekiwane i mile widziane. Większość webmasterów tworzy swoje witryny tak, aby były przyjazne dla Googlebota, aby uzyskać wyższą pozycję w wynikach wyszukiwania. Przyszłość robotów internetowych jest poza planami; Twórcy botów stale wprowadzają innowacje. Obecne boty mogą czytać e-maile, wysyłać e-maile, podążać za linkami, wypełniać formularze, monitorować strony internetowe, pobierać pliki i przechwytywać obrazy. Jeśli informacje są dostępne w Internecie, prędzej czy później odwiedzi je bot. Można sobie tylko wyobrazić, co Google może zebrać z całego Internetu po latach i dziesięcioleciach gromadzenia.