https://szkolazpieklarodem.pl/
Zanim faktycznie przejdziemy do kodowania części Rasa Core dla naszego modelu zarządzania dialogiem, naprawdę ważne jest, aby zrozumieć, dlaczego i skąd to się bierze. Spróbujemy zrozumieć, jak do tej pory robiliśmy wszystko, aby zbudować chatboty i jak to się zmieni na zawsze. Weźmy przykład:
Gdybyśmy mieli zbudować prostego chatbota, który pomógłby użytkownikom zarezerwować bilety lotnicze/autobusowe/filmowe/kolejowe, najłatwiej byłoby stworzyć maszynę stanów lub drzewa decyzyjne, napisać kilka if…else i gotowe. To by zadziałało, ale nie byłoby skalowalne. Jeśli klient ma początkowo dobre doświadczenia z czymś, chce częściej z tego korzystać. Za pomocą niektórych heurystyk możemy wykazać, że chatbot jest inteligentny, ale nie na długo. Kiedy przepływ kontrolny kodu przechodzi z bloku try do bloku wyjątkiem, zaczynamy drapać się po głowie. Rysunek przedstawia prostą prezentację tego, jak może wyglądać maszyna stanu służąca do zbudowania tego chatbota.
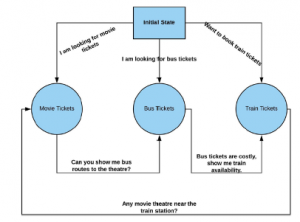
Jeśli spojrzymy na nasz diagram stanu, może to zadziałać w przypadku normalnej rozmowy, w której użytkownik szuka biletów do kina, autobusu lub pociągu albo chce zarezerwować bilet autobusowy po zapytaniu o bilety do kina. Co się stanie, jeśli użytkownik poprosi jednocześnie o bilety na autobus i do kina? Można powiedzieć, że możemy dodać jeszcze kilka instrukcji if…else do naszego już zagnieżdżonego kodu, aby sobie z tym poradzić. Jeśli jesteś dobrym programistą, zapisanie wejścia-wyjścia z maszyny stanowej lub rozszerzenie drzewa decyzyjnego nie zajmie Ci dużo czasu. Ale pomyśl o sytuacji, gdy te warunki zaczynają rosnąć wykładniczo i musisz ciągle dodawać przypadki, aby sobie z tym poradzić, a one również zaczynają się wzajemnie zakłócać. Nasz mózg działa w taki sposób, że uczymy się i uczymy na nowo. Jeśli dziecko nie wie, co zrobi z nim ogień, dotyka go, ale gdy go zaboli, nie robi tego więcej. Utwierdzają w przekonaniu, że jest to szkodliwe. Podobnie działa to w przypadku nagród – gdy coś zrobisz i coś otrzymasz, kojarzysz fakt, że zrobienie czegoś przynosi nagrodę lub lepszą nagrodę, a potem masz zamiar zrobić to ponownie. Nazywa się to uczeniem przez wzmacnianie w ML, gdzie maszyna uczy się, jak zachować się w określonej sytuacji, wykonując działania i rozumiejąc wyniki. Uczenie się przez wzmacnianie czasami nie jest najlepszym podejściem, na przykład w sytuacjach, gdy dane nie są wystarczające do nauczenia się, jakość danych jest niewystarczająca do nauczenia się scenariuszy nagród itp.