GoLang V
Operatory i struktury kontrolne
Operatory w Go
Operatory są budulcem każdego języka programowania. W efekcie bez użycia operatorów funkcjonalność języka Go jest niepełna. Operatory pozwalają nam wykonywać wiele działań na operandach. Operatory w języku programowania Go są klasyfikowane na podstawie ich funkcjonalności:
o Operatory arytmetyczne
o Operatorzy relacyjni
o Różni operatorzy
o Operatory bitowe
o Operatorzy przypisania
o Operatory logiczne
Operatory arytmetyczne
W Go są one używane do wykonywania operacji arytmetycznych/matematycznych na operandach:
o Dodawanie: Operator "+" łączy ze sobą dwa operandy. Na przykład x+y.
o Odejmowanie: Operator "-" bierze dwa operandy i odejmuje je. Na przykład x-y.
o Mnożenie: Znak "*" służy do mnożenia dwóch operandów. Na przykład, x*y.
o Dzielenie: Operator "/" dzieli pierwszy operand przez drugi operand. Jako przykład rozważmy x/y.
o Moduł: Kiedy pierwszy operand jest dzielony przez drugi, zwracana jest reszta operatora "%". Na przykład x procent y.
Nota bene: -, +, !, &, * i - są również znane jako operatory jednoargumentowe i mają wyższy priorytet. Ponieważ operatory ++ i -- pochodzą z instrukcji, a nie z wyrażeń; znajdują się poza hierarchią operatorów.
Przykład:
// Program to illustrate the
// use of the arithmetic operators
package main
import "fmt"
func main()
{
x:= 37
y:= 22
// Addition
result1:= x + y
fmt.Printf("Result of x + y = %d", result1)
// Subtraction
result2:= x - y
fmt.Printf("\nResult of x - y = %d", result2)
// Multiplication
result3:= x * y
fmt.Printf("\nResult of x * y = %d", result3)
// Division
result4:= x / y
fmt.Printf("\nResult of x / y = %d", result4)
// Modulus
result5:= x % y
fmt.Printf("\nResult of x %% y = %d", result5)
}
Operatory relacyjne>
Podczas porównywania dwóch wartości stosowane są operatory relacyjne. Przyjrzyjmy się im:
o Operator "==" (równy) określa, czy dwa operandy są równe. W takim przypadku zwraca wartość true. Jeśli nie, zwraca false. 6==6 zwróci na przykład prawdę.
o Operator "!=" określa, czy dwa podane operandy są równe, czy nie. Jeśli tak, zwraca wartość true. Jeśli nie, zwraca false. Jest to logiczny odpowiednik operatora "==". 6!=6 zwróci na przykład fałsz.
o Operator ">" (Większy niż) określa, czy pierwszym argumentem jest większy niż drugi. W takim przypadku zwraca wartość true. Jeśli nie, zwraca fałsz. 7>6 da na przykład prawdę.
o Operator "<" (Mniej niż) określa, czy pierwszy operand jest mniejszy niż drugi. W takim przypadku zwraca wartość true. Jeśli nie, zwraca false. Na przykład 6<4 zwróci fałsz.
o Operator "?" (Większy niż równy) określa, czy pierwszy operand jest większy lub równy drugiemu operandowi, a następnie zwraca prawdę. Jeśli nie, zwraca false. 6?6 zwróci na przykład prawdę. o Operator "?" (najmniejszy niż równy) określa, czy pierwszy operand jest mniejszy lub równy drugiemu operandowi, a następnie zwraca wartość true. Jeśli nie, zwraca false. Na przykład 6?6 również zwróci wartość true.
Przykład:
// Program to illustrate
// the use of relational operators
package main
import "fmt"
func main() {
x:= 38
y:= 25
// '=='(Equal To)
result1:= x == y
fmt.Println(result1)
// '!='(Not Equal To)
result2:= x != y
fmt.Println(result2)
// '<'(Less Than)
result3:= x < y
fmt.Println(result3)
// '>'(Greater Than)
result4:= x > y
fmt.Println(result4)
// '>='(Greater Than Equal To)
result5:= x >= y
fmt.Println(result5)
// '<='(Less Than Equal To)
result6:= x <= y
fmt.Println(result6)
}
Operatory logiczne
Służą do zintegrowania dwóch lub więcej warunków/ograniczeń lub uzupełnienia oceny pierwotnego warunku.
o Logiczne AND: Operator && zwraca wartość true, gdy spełnione są oba rozważane warunki. Jeśli nie, zwraca false. x && y, na przykład, zwraca wartość true, gdy zarówno x, jak i y są prawdziwe (tj. niezerowe).
o Logiczne LUB: Gdy spełniony jest jeden lub oba wymagania, operator "||" zwraca wartość true. Jeśli nie, zwraca false. Na przykład x || y zwraca true, jeśli x lub y jest prawdziwe (tj. niezerowe). Oczywiście zwraca wartość true, jeśli zarówno x, jak i y są prawdziwe.
o Logiczne NIE: Jeśli dany warunek jest spełniony, operator "!" zwraca prawdę. Jeśli nie, zwraca false. !x, na przykład, zwraca wartość true, jeśli a jest fałszywe, czyli gdy x=0.
Przykład:
// Program to illustrate
//the use of logical operators
package main
import "fmt"
func main() {
var x int = 26
var y int = 65
if(x!=y && x<=y){
fmt.Println("True")
}
if(x!=y || x<=y){
fmt.Println("True")
}
if(!(x==y)){
fmt.Println("True")
}
}
Operatory bitowe
W języku programowania Go 6 operatorów bitowych działa na poziomie bitowym lub wykonuje operacje bit po bicie. Operatory bitowe to:
o & (bitowe AND): Pobiera dwa operandy i wykonuje operację AND na każdym bicie dwóch liczb. AND zwraca 1 tylko wtedy, gdy oba bity są równe 1.
o | (bitowe LUB): Pobiera dwa operandy i wykonuje LUB na każdym bicie dwóch liczb całkowitych. LUB zwraca wartość 1, jeśli jeden z dwóch bitów ma wartość 1.
o ^ (bitowe XOR): Pobiera dwa operandy i wykonuje XOR na każdym bicie dwóch liczb. Jeśli dwa bity są różne, wynikiem operacji XOR jest 1.
o << (przesunięcie w lewo): przyjmuje dwie liczby całkowite, przesuwa w lewo bity pierwszego operandu, a drugi operand określa liczbę przesunąć pozycji.
o >> (przesunięcie w prawo): pobiera dwie liczby, przesuwa bity pierwszego operandu w prawo, a liczba miejsc do przesunięcia jest określana przez drugi operand.
o &^ (AND NOT): Jest to prosty operator.
Przykład:
// Program to illustrate
// the use of bitwise operators
package main
import "fmt"
func main() {
x:= 34
y:= 20
// & (bitwise AND)
result1:= x & y
fmt.Printf("Result of x & y = %d", result1)
// | (bitwise OR)
result2:= x | y
fmt.Printf("\nResult of p | q = %d", result2)
// ^ (bitwise XOR)
result3:= p ^ q
fmt.Printf("\nResult of x ^ y = %d", result3)
// << (left shift)
result4:= x << 1
fmt.Printf("\nResult of x << 1 = %d", result4)
// >> (right shift)
result5:= x >> 1
fmt.Printf("\nResult of x >> 1 = %d", result5)
// &^ (AND NOT)
result6:= x &^ y
fmt.Printf("\nResult of x &^ y = %d", result6)
}
Operatory przypisania
Podczas przypisywania wartości do zmiennej stosowane są operatory przypisania. Lewy operand operatora przypisania jest zmienną, a prawy operand operatora przypisania jest wartością. Wartość po prawej stronie musi mieć ten sam typ danych co zmienna po lewej stronie, w przeciwnym razie kompilator zgłosi błąd. Oto przykłady operatorów przypisania:
o "=" (Proste przypisanie): Najbardziej podstawowy operator przypisania. Wartość po prawej stronie jest przypisywana do zmiennej po lewej stronie za pomocą tego operatora.
o "+=" (Dodaj przypisanie): Kombinacja operatorów "+" i "=". Ten operator najpierw dodaje zmienną po lewej stronie bieżącej wartości do prawej, a następnie przypisuje wynik do zmiennej po lewej stronie.
o "-=" (odejmowanie przypisania): Kombinacja operatorów "?" i "=". Ten operator odejmuje bieżącą wartość zmiennej po lewej stronie od prawej, a następnie przypisuje wynik zmiennej po lewej stronie.
o "*=" (przypisanie mnożenia): Kombinacja operatorów "*" i "=". Ten operator najpierw mnoży zmienną po lewej przez prawą, a następnie przypisuje wynik do lewej zmiennej.
o "/=" (przypisanie dzielenia): Kombinacja operatorów "/" i "=". Ten operator dzieli zmienną po lewej stronie bieżącą wartość przez wartość po prawej stronie, a następnie przypisuje wynik zmiennej po lewej stronie.
o "%=" (przypisanie modułu): Ten operator łączy w sobie operatory "%" i "=". Operator ten mnoży aktualną wartość zmiennej po lewej przez prawą, a następnie przypisuje wynik do lewej zmiennej.
o "&=" (przypisanie bitowe AND): kombinacja "&" i "=" operatorzy. Ten operator "Bitwise AND" bieżąca wartość do lewej zmiennej do prawej przed przypisaniem wyniku do lewej zmiennej.
o "=" (bitowe wyłączne LUB): Kombinacja operatorów "=" i "=". Ten operator "Bitwise Exclusive OR" przestawia bieżącą wartość lewej zmiennej na prawą przed przypisaniem wyniku do lewej zmiennej.
o "|=" (bitowo włącznie OR): Kombinacja operatorów "|" i "=". Ten operator "Bitwise Inclusive OR" przestawia bieżącą wartość lewej zmiennej na prawą przed przypisaniem wyniku do lewej zmiennej.
Przykład:
// Program to illustrate
// the use of assignment operators
package main
import "fmt"
func main()
{
var x int = 49
var y int = 54
// "="(Simple Assignment)
x = y
fmt.Println(p)
// "+="(Add Assignment)
x += y
fmt.Println(x)
//"-="(Subtract Assignment)
x-=y
fmt.Println(x)
// "*="(Multiply Assignment)
x*= y
fmt.Println(x)
// "/="(Division Assignment)
x /= y
fmt.Println(x)
// "%="(Modulus Assignment)
x %= y
fmt.Println(x)
}
Różne operatorzy
o &: Ten operator zwraca adres zmiennej.
o *: Ten operator zwraca wskaźnik do zmiennej.
o <-: Otrzymano nazwę tego operatora. Służy do pobierania wartości z kanału.
Przykład:
// Program to illustrate
// the use of Misc Operators
package main
import "fmt"
func main() {
x := 6
// Using address of operator(&) and
// pointer indirection(*) operator
y := &x
fmt.Println(*y)
*y = 7
fmt.Println(x)
}
INSTRUKCJE STERUJĄCE
Programista musi zdefiniować jeden lub więcej warunków, które mają być ocenione lub przetestowane przez program, instrukcję lub instrukcje, które zostaną wykonane, jeśli warunek zostanie uznany za prawdziwy, oraz opcjonalnie dalsze instrukcje, które zostaną wykonane, jeśli warunek zostanie uznany za fałszywy. Poniżej przedstawiono ogólną formę wspólnych ram podejmowania decyzji obecnych w większości języków programowania.
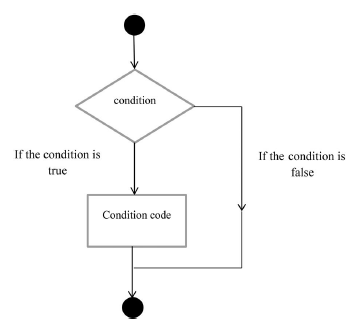
Język programowania Go obsługuje następujące instrukcje decyzyjne.
Nr: instrukcja i opis
1: instrukcja if: Po wyrażeniu boolowskim następuje jedna lub więcej instrukcji w instrukcji if.
2 : instrukcja if...else : Gdy wyrażenie boolowskie jest fałszywe, po instrukcji if następuje opcjonalna instrukcja else.
3 : zagnieżdżone instrukcje if : Instrukcja if lub else if może być używana wewnątrz innej instrukcji if lub else if.
4 : instrukcja switch : instrukcja switch sprawdza zmienną pod kątem równości względem zbioru wartości.
5 : instrukcja select : instrukcja select jest podobna do instrukcji switch; jednak opisy przypadków odnoszą się do komunikacji kanałowej.
Instrukcja if
Jest to najprostsze stwierdzenie decyzyjne. Służy do decydowania, czy określona instrukcja lub blok instrukcji zostanie wykonany, tj. jeśli dany warunek jest prawdziwy, to blok instrukcji zostanie wykonany, w przeciwnym razie nie.
Składnia:
if (warunek)
{
// Instrukcja do wykonania, jeśli warunek jest prawdziwy
}
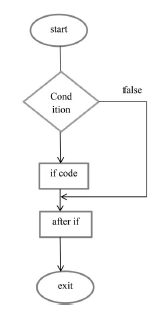
Przykład :
// Program to illustrate
//the use of if statement
package main
import "fmt"
func main() {
// taking local variable
var v int = 800
// using the if statement for
// checking condition
if(v < 2000) {
// print following if
// condition evaluates to true
fmt.Printf("v is less than 2000\n")
}
fmt.Printf("Value of v is : %d\n", v)
}
Instrukcja if
else
Instrukcja if sama w sobie informuje nas, że warunek jest prawdziwy, zostanie wykonany blok instrukcji; jeśli warunek jest fałszywy, blok instrukcji nie zostanie wykonany. Ale co, jeśli warunek jest fałszywy i chcemy zrobić coś innego? W tym momencie pojawia się instrukcja else. Gdy warunek jest fałszywy, możemy użyć instrukcji else w połączeniu z instrukcją if, aby uruchomić blok kodu.
Składnia:
if (warunek)
{
// Wykonuje ten blok if
// warunek jest prawdziwy
} w przeciwnym razie {
// Wykonuje ten blok if
// warunek jest fałszywy
}
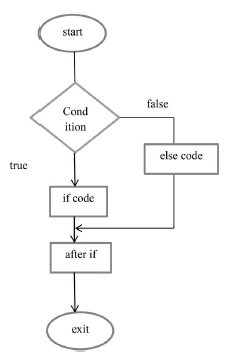
Przykład :
// Program to illustrate
// the use of if...else statement
package main
import "fmt"
func main() {
// taking a local variable
var v int = 2400
// using the if statement for
// checking condition
if(v < 2000) {
// print following if
// the condition evaluates to true
fmt.Printf("v is less than 2000\n")
} else {
// print following if
// the condition evaluates to true
fmt.Printf("v is greater than 2000\n")
}
}
Zagnieżdżona instrukcja if
W Go zagnieżdżone if jest instrukcją if, która jest celem innego wyrażenia if lub else. Instrukcja if zagnieżdżona w innej instrukcji if jest nazywana zagnieżdżoną instrukcją if. Tak, możemy zagnieżdżać instrukcje if w instrukcjach if w GoLang. Innymi słowy, możemy zagnieździć instrukcję if w innej instrukcji if.
Składnia:
if (condition1) {
// Executes when the condition1 is true
if (condition2) {
// Executes when the condition2 is true
}
}
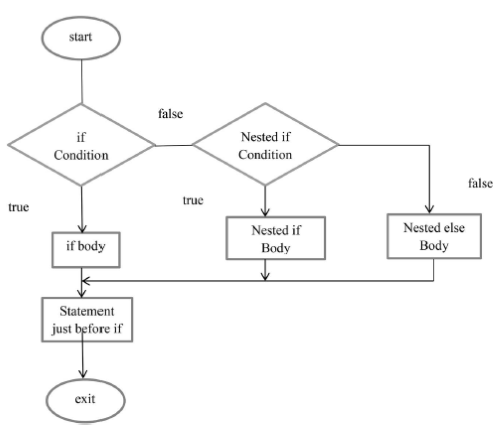
Przykład :
// Program to illustrate
// the use of nested if statement
package main
import "fmt"
func main() {
// taking the two local variable
var v1 int = 500
var v2 int = 800
// using if statement
if( v1 == 600 ) {
// if condition is true then
// check the following
if( v2 == 800 ) {
// if the condition is true
// then display following
fmt.Printf("Value of v1 is 500 and v2 is
800\n" );
}
}
}
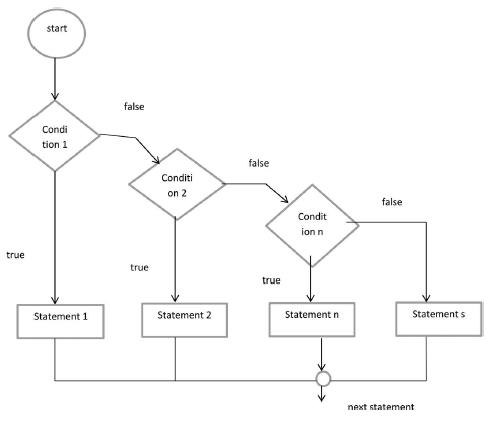
Użytkownik może tutaj wybierać spośród wielu alternatyw. Instrukcje if są wykonywane w podanej kolejności. Gdy spełniony jest jeden z warunków, wykonywana jest instrukcja związana z tym if; reszta drabiny jest pomijana. Jeśli żadne z wymagań nie jest spełnione, wykonywana jest ostatnia instrukcja else.
Ważne notatki:
o Instrukcja if może mieć wartość zero lub jeden i musi wystąpić po każdej innej instrukcji if.
o Instrukcja else if w instrukcji if może zawierać od zera do wielu innych instrukcji if i musi wystąpić przed klauzulą else.
o Jeśli instrukcja else if powiedzie się, nie ma potrzeby wypróbowywania żadnej z pozostałych instrukcji else if lub else.
Składnia:
if(condition_1) {
// this block will execute when the
condition_1 is true
} else if(condition_2) {
// this block will execute when the condition2
is true
}
.
else {
// this block will execute when none
// of condition is true
}
Przykład:
// Program to illustrate
// the use of if..else..if ladder
package main
import "fmt"
func main() {
// taking a local variable
var v1 int = 800
// checking condition
if(v1 == 120) {
// if condition is true then
// display following */
fmt.Printf("Value of v1 is 120\n")
} else if(v1 == 250) {
fmt.Printf("Value of a is 250\n")
} else if(v1 == 310) {
fmt.Printf("Value of a is 310\n")
} else {
// if none of the conditions is true
fmt.Printf("None of values is matching\n")
}
}
Przejdź do pętli GoLang
Język programowania Go ma tylko jedną pętlę, którą jest pętla for. Pętla for jest formą struktury kontroli powtórzeń, która pozwala nam zaprojektować pętlę, która zostanie wykonana określoną liczbę razy. Ta pętla for może być używana na kilka sposobów w języku programowania Go, w tym:
1. Jak najbardziej podstawowa pętla for: jest porównywalna z tym, co widzimy w innych językach programowania, takich jak C, C++, C#, Java itp.
Składnia:
for initialization; condition; post{
// statement
}
Tutaj instrukcja inicjalizacji jest opcjonalna i jest uruchamiana przed rozpoczęciem pętli for. Instrukcja inicjalizacji jest zawsze zawarta w instrukcji podstawowej, takiej jak deklaracje zmiennych, instrukcje inkrementacji lub przypisania lub wywołania funkcji. Instrukcja warunku zawiera wyrażenie logiczne oceniane na początku każdej iteracji pętli. Pętla jest wykonywana, jeśli wartość instrukcji warunkowej jest prawdziwa. Instrukcja post jest wykonywana po treści pętli for. Po oświadczeniu post, oświadczenie warunku jest ponownie oceniane; jeśli wartość instrukcji warunkowej jest fałszywa, pętla zostaje zakończona.
Przykład:
/ Program to illustrate
// the use of simple for loop
package main
import "fmt"
// the main function
func main() {
// for loop
// This loop starts when x = 0
// executes till x<4 condition is true
// post statement is x++
for x := 0; x < 4; x++{
fmt.Printf("helloeveryone\n")
}
}
2. Pętla for jako pętla nieskończona: Usuwając wszystkie trzy wyrażenia z pętli for, pętla for może być wykorzystana jako pętla nieskończona. Gdy użytkownik nie umieści instrukcji warunku w pętli for, oznacza to, że instrukcja warunku jest prawdziwa, a pętla wchodzi w pętlę nieskończoną.
Składnia:
for
{
// (Instrukcje)
}
Przykład:
// Program to illustrate
// the use of an infinite loop
package main
import "fmt"
// the main function
func main() {
// infinite loop
for {
fmt.Printf("Helloeveryone\n")
}
}
3. Pętla while for: Pętla for może być również używana jako pętla while. Pętla ta jest powtarzana aż do spełnienia określonego warunku. Pętla kończy się, gdy wartość podanego warunku jest fałszywa.
Składnia:
for warunek {
// instrukcje
}
Przykład:
/ Program to illustrate
// for loop as while Loop
package main
import "fmt"
// the main function
func main() {
// while loop for loop executes till
// x < 3 condition is true
x:= 0
for x < 3 {
x += 2
}
fmt.Println(x)
}
4. Prosty zakres w pętli for: Zakres może być również użyty w pętli.
Składnia:
for x, y:= zakres zmiennej{
// instrukcje
}
Tutaj zmienne x i y są miejscem przechowywania wartości iteracji. Są one czasami określane jako zmienne iteracyjne. Druga zmienna, y, nie jest wymagana. Przed rozpoczęciem pętli wyrażenie zakresu jest oceniane raz.
Przykład:
// Program to illustrate
// the use of simple range loop
package main
import "fmt"
// the main function
func main() {
// Here rvariable is array
rvariable:= []string{"HEW", "Hello",
"Helloeveryoneworld"}
// x and y stores the value of rvariable
// x store index number of individual string
and
// y store individual string of the given
array
for x, y:= range rvariable {
fmt.Println(x, y)
}
}
5. Używanie pętli for dla napisów: Pętla for może iterować po punkcie kodowym łańcucha Unicode .
Składnia:
for index chr:= zakres str{
// instrukcje}
W tym przypadku indeks jest zmienną przechowującą pierwszy bajt punktu kodowego zakodowanego w UTF-8, chr jest zmienną przechowującą znaki podanego ciągu, a str jest ciągiem.
Przykład:
// Program to illustrate
// the use for loop using string
package main
import "fmt"
// the main function
func main() {
// String as range in the for loop
for x, y:= range "XxyCd" {
fmt.Printf("Index number of %U is %d\n",
y, x)
}
}
6. Dla map: Pętla for może przechodzić przez parę klucz i wartość mapy.
Składnia:
for klucz, wartość := zakres map {
// instrukcje
}
Przykład:
// Program to illustrate
// the use for loop using maps
package main
import "fmt"
// the main function
func main() {
// using the maps
mmap := map[int]string{
22:"Peeks",
33:"POP",
44:"PeeksofPeeks",
}
for key, value:= range mmap {
fmt.Println(key, value)
}
}
7. For channel: Pętla for może iterować po kolejnych danych przesyłanych w kanale, aż kanał zostanie zamknięty.
Składnia:
for item := range Chnl {
// statement(s)
}
Przykład:
// program to illustrate
// the use for loop using channel
package main
import "fmt"
// the main function
func main() {
// using the channel
chnl := make(chan int)
go func(){
chnl <- 1000
chnl <- 10000
chnl <- 100000
chnl <- 1000000
close(chnl)
}()
for x:= range chnl {
fmt.Println(x)
}
}
Ważne notatki:
o Nawiasy nie obejmują trzech instrukcji pętli for.
o Pętla wymaga nawiasów klamrowych.
o Nawias otwierający i instrukcja post powinny znajdować się w tej samej linii.
o Jeśli tablica, łańcuch, wycinek lub mapa są puste, pętla for nie zgłasza błędu i kontynuuje swój przebieg. Innymi słowy, jeśli tablica, łańcuch, wycinek lub mapa mają wartość zero, liczba iteracji pętli for wynosi zero.
Instrukcja switch Go
Instrukcja switch jest przykładem wielokierunkowej instrukcji rozgałęzienia. Oferuje efektywną metodę przenoszenia wykonania do różnych obszarów kodu w zależności od wartości wyrażenia. Język programowania Go pozwala na dwa rodzaje instrukcji switch:
o Przełącznik ekspresji
o Przełącznik typu
Wyrażenie switch
Wyrażenie switch jest analogiczne do instrukcji switch w C, C++ i Javie. Pozwala nam efektywnie kierować wykonanie do różnych obszarów kodu w oparciu o wartość wyrażenia.
Składnia:
switch optstatement; optexpression{
case expression1: Statement
case expression2: Statement
.
.
default: Statement
}
Ważne notatki:
o W przełączniku wyrażeń zarówno optstatement, jak i optexpression są wyrażeniami opcjonalnymi.
o Jeśli występują zarówno optstatement, jak i optexpression, należy je rozdzielić średnikiem (;).
o Jeśli w przełączniku nie ma wyrażenia, kompilator zakłada, że wyrażenie jest prawdziwe.
o Instrukcja opcjonalna, często znana jako optstatement, zawiera podstawowe instrukcje, takie jak deklaracje zmiennych, instrukcje przyrostu lub przypisania, wywołania funkcji itp.
o Jeśli zmienna pojawia się w instrukcji opcjonalnej, jej zakres jest ograniczony do tej instrukcji switch.
o Nie ma instrukcji break w instrukcji case i default instrukcji switch. Możemy jednak użyć instrukcji break i fallthrough, jeśli wymaga tego nasza aplikacja.
o W instrukcji switch instrukcja default jest opcjonalna.
o Sprawa może mieć wiele wartości oddzielonych przecinkiem (,).
o Jeśli przypadek nie zawiera wyrażenia, kompilator zakłada, że wyrażenie jest prawdziwe.
Pierwszy przykład:
// Program to illustrate
// the concept of Expression switch statement
package main
import "fmt"
func main() {
// the switch statement with both
// optional statement, i.e, day:=4
// and the expression, i.e, day
switch day:=5; day{
case 1:
fmt.Println("Sunday")
case 2:
fmt.Println("Monday")
case 3:
fmt.Println("Tuesday")
case 4:
fmt.Println("Wednesday")
case 5:
fmt.Println("Thursday")
case 6:
fmt.Println("Friday")
case 7:
fmt.Println("Saturday")
default:
fmt.Println("Invalid")
}
}
Drugi przykład :
// Program to illustrate
// the concept of Expression switch statement
package main
import "fmt"
func main() {
var value int = 3
// Switch statement without an
// optional statement and expression
switch {
case value == 1:
fmt.Println("Hey")
case value == 2:
fmt.Println("Hello")
case value == 3:
fmt.Println("Namstae")
default:
fmt.Println("Invalid")
}
}
Trzeci przykład:
// Program to illustrate
// the concept of Expression switch statement
package main
import "fmt"
func main() {
var value string = "four"
// Switch statement without the default
statement
// Multiple values in the case statement
switch value {
case "one":
fmt.Println("C")
case "two", "three":
fmt.Println("C#")
case "four", "five", "six":
fmt.Println("Go")
}
}
Przełącznik typu
Podczas porównywania typów stosowany jest przełącznik typu. Przypadek w tym przełączniku obejmuje typ, który będzie porównywany z typem w wyrażeniu przełącznika.
Składnia :
switch optstatement; typeswitchexpression{
case typelist 1: Statement
case typelist 2: Statement
.
.
default: Statement
}
Ważne notatki:
o Instrukcja opcjonalna, w skrócie optstatement, jest porównywalna z wyrażeniem switch.
o Sprawa może mieć wiele wartości oddzielonych przecinkiem (,).
o Instrukcje case i default w instrukcji typu switch nie zawierają instrukcji break. Możemy jednak użyć instrukcji break i fallthrough, jeśli wymaga tego nasza aplikacja.
o W instrukcji typu switch instrukcja default jest opcjonalna.
o Typeswitchexpression jest wyrażeniem, które w konsekwencji tworzy typ.
o Jeśli wyrażenie jest przypisane do zmiennej w typeswitchexpression za pomocą operatora :=, typ tej zmiennej jest określany przez typ zawarty w klauzuli case. Jeśli klauzula case zawiera dwa lub więcej typów, typem zmiennej jest typ, w którym została ona wygenerowana w typeswitchexpression.
Przykład:
// Program to illustrate
// the concept of Type switch statement
package main
import "fmt"
func main() {
var value interface{}
switch x:= value.(type) {
case bool:
fmt.Println("The value is of boolean type")
case float64:
fmt.Println("The value is of float64 type")
case int:
fmt.Println("value is of int type")
default:
fmt.Printf("value is of type: %T", x)
}
}
GoLang VII
Funkcje i rekurencja
Przejdź do FUNKCJE JĘZYKOWE
Funkcje to często bloki kodu lub instrukcje w programie, które umożliwiają użytkownikowi ponowne użycie tego samego kodu, oszczędzając pamięć, oszczędzając czas i, co najważniejsze, poprawiając czytelność kodu. Funkcja jest w istocie zbiorem instrukcji, które wykonują dane zadanie i dostarczają wynik wywołującemu. Funkcja może również wykonać określone zadanie bez zwracania żadnych wyników.
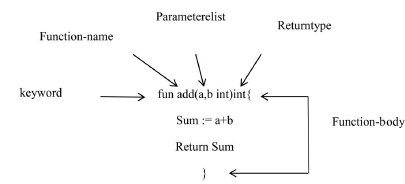
Deklaracja funkcji
Deklaracja funkcji jest metodą konstruowania funkcji.
Składnia:
func nazwa-funkcji(Parameterlist)(Returntype){
// ciało funkcji
}
W deklaracji funkcji znajdują się:
o func: Jest to słowo kluczowe w języku programowania Go używane do definiowania funkcji.
o nazwa-funkcji: To jest nazwa funkcji.
o Lista parametrów: Określa nazwę i typ argumentów funkcji.
o Returntype: Ten parametr jest opcjonalny i zawiera typy wartości zwracanych przez funkcję. Jeśli zamierzamy użyć zwracanego typu w naszej funkcji będziemy musieli dołączyć instrukcję return
Wywoływanie funkcji
Kiedy użytkownik chce wykonać funkcję, wywołuje ją lub wywołuje. Aby skorzystać z możliwości funkcji, należy ją wywołać. Jak pokazano w poniższym przykładzie, mamy funkcję o nazwie area() z dwoma parametrami. Teraz nazywamy tę funkcję po imieniu w funkcji main, tj. area(13, 11) z dwoma parametrami.
Przykład:
// Program to illustrate
// the use of function
package main
import "fmt"
// area() is used to find
// area of rectangle
// area() function two parameters,
// i.e, length and width
func area(length, width int)int{
arr := length* width
return arr
}
// the main function
func main() {
// Display area of the rectangle
// with the method calling
fmt.Printf("Area of rectangle is : %d",
area(13, 11))
}
Argumenty funkcji
Argumenty dostarczane do funkcji nazywane są w Go parametrami rzeczywistymi, podczas gdy parametry odbierane przez funkcję nazywane są parametrami formalnymi.
Uwaga: język Go domyślnie używa techniki call by value aby przekazać parametry w funkcji.
Język programowania Go udostępnia dwie metody przekazywania parametrów do naszej funkcji.
Wywołanie według wartości
W ten sposób przekazywania parametrów wartości parametrów rzeczywistych są przekazywane do parametrów formalnych funkcji, a dwa rodzaje parametrów są przechowywane w różnych miejscach pamięci. W rezultacie wszelkie zmiany dokonane w obrębie funkcji nie znajdują odzwierciedlenia w rzeczywistych argumentach wywołujących.
Przykład:
// Program to illustrate
// the concept of call by value
package main
import "fmt"
// function which swap the values
func swap(x, y int)int{
var o int
o= x
x=y
y=o
return o
}
// the main function
func main() {
var a int = 20
var b int = 30
fmt.Printf("a = %d and b = %d", a, b)
// call by values
swap(a, b)
fmt.Printf("\n a = %d and b = %d",a, b)
}
Wywołanie przez referencje
Ponieważ zarówno parametry rzeczywiste, jak i parametry formalne odnoszą się do identycznych lokalizacji, wszelkie zmiany dokonane w ramach funkcji mają odzwierciedlenie w rzeczywistych parametrach wywołującego.
Przykład:
// Program to illustrate
// the concept of call by reference
package main
import "fmt"
// function which swap the values
func swap(x, y *int)int{
var o int
o = *x
*x = *y
*y = o
return o
}
// the main function
func main() {
var a int = 20
var b int = 10
fmt.Printf("a = %d and b = %d", a, b)
// call by reference
swap(&a, &b)
fmt.Printf("\n a = %d and b = %d", a, b)
}
FUNKCJA ZWRACAJĄCA WIELE WARTOŚCI
Instrukcja return w języku programowania Go pozwala nam zwrócić wiele wartości z funkcji. Innymi słowy, pojedyncza instrukcja return w funkcji może zwrócić wiele wartości. Zwracane wartości są tego samego typu, co parametry podane na liście parametrów.
Składnia:
func functionname(parameterlist)(returntypelist){
// code…
}
Przykład:// Program to illustrate how a
// function return the multiple values
package main
import "fmt"
// myfunc return 3 values of int type
func myfunc(x, y int)(int, int, int ){
return x - y, x * y, x + y
}
// the main Method
func main() {
// return values are assigned into different
variables
var myvar1, myvar2, myvar3 = myfunc(4, 2)
// Display-values
fmt.Printf("The Result is: %d", myvar1 )
fmt.Printf("\nThe Result is: %d", myvar2)
fmt.Printf("\nThe Result is: %d", myvar3)
}
Nadawanie nazw zwracanym wartościom
Zwracanym wartościom w języku programowania Go można nadać nazwy. Takich nazw zmiennych możemy używać również w naszym kodzie. Nie jest wymagane dołączanie instrukcji return do tych identyfikatorów, ponieważ kompilator Go rozpozna, że te zmienne muszą zostać odesłane. Nagi powrót to nazwa nadana tej formie zwrotu. Zastosowanie samego zwrotu minimalizuje redundancję w naszym programie.
Składnia:
func functionname(para1, para2 int)(name1 int, name2 int){
// code
}
name1 i name2 to nazwy zwracanych wartości, podczas gdy para1 i para2 to argumenty funkcji.
Przykład:
// illustrate how to give names to return values
package main
import "fmt"
// myfunc return 2 values of the int type
// here, return value name
// is rectangle & square
func myfunc(x, y int)( rectangle int, square int )
{
rectangle = x*y
square = x*x
return
}
func main() {
// The return values are assigned into the two
different variables
var area1, area2 = myfunc(4, 8)
// Display the values
fmt.Printf("Area of the rectangle is: %d",
area1 )
fmt.Printf("\nThe Area of the square is: %d",
area2)
}
FUNKCJE ZMIENNE
Funkcja wariadyczna to taka, która jest wywoływana ze zmienną liczbą parametrów. Innymi słowy, funkcja variadic akceptuje zero lub więcej danych wejściowych od użytkownika. fmt. Printf jest przykładem funkcji wariadycznej; wymaga jednego stałego argumentu na początku i może zaakceptować dowolną liczbę argumentów później.
Ważne notatki:
o Ostatni typ parametru w deklaracji funkcji variadic jest poprzedzony wielokropkiem, czyli (
). Oznacza to, że funkcja może być wywoływana z dowolną liczbą tego rodzaju parametrów.
Składnia:
function function-name(para1, para2...type)type{
// code
}
o W ramach funkcji
typ działa podobnie do plasterka. Załóżmy, że mamy sygnaturę funkcji, taką jak add(b…nt)int, a argument a jest typu []int.
o W funkcji variadic możesz również podać istniejący wycinek. Jak pokazano w drugim przykładzie, wysyłamy wycinek całej tablicy do funkcji, aby to zrobić.
o Gdy do funkcji variadic nie są przekazywane żadne argumenty, wycinek w obrębie funkcji jest równy zero.
o Funkcje wariacyjne są powszechnie używane do formatowania ciągów znaków.
o W metodzie variadycznej można również przekazać kilka przekrojów.
o Parametry Variadic nie mogą być używane jako wartości zwracane, chociaż mogą być zwracane jako wycinki.
Pierwszy przykład:
// Program to illustrate
// the concept of variadic function
package main
import(
"fmt"
"strings"
)
// Variadic function to join the strings
func joinstr(element...string)string{
return strings.Join(element, "-")
}
func main() {
// zero argument
fmt.Println(joinstr())
// the multiple arguments
fmt.Println(joinstr("Hello", "HEW"))
fmt.Println(joinstr("Hello", "Everyone",
"World"))
fmt.Println(joinstr("H", "E", "L", "L", "O"))
}
Drugi przykład:
// Program to illustrate
// the concept of variadic function
package main
import(
"fmt"
"strings"
)
// The Variadic function to join strings
func joinstr(element...string)string{
return strings.Join(element, "-")
}
func main() {
// pass a slice in the variadic function
element:= []string{"hello", "FROM", "world"}
fmt.Println(joinstr(element…))
}
Kiedy korzystamy z funkcji variadic:
o Funkcja variadic służy do przekazywania wycinka w funkcji.
o Używamy funkcji zmiennej, gdy nie znamy liczby parametrów.
o Kiedy używamy funkcji zmiennej w twoim oprogramowaniu, poprawia się czytelność.
Funkcje anonimowe
Funkcja anonimowa jest cechą języka programowania Go. Funkcja anonimowa nie ma nazwy, gdy musimy napisać funkcję wbudowaną. Anonimowa funkcja w Go może skonstruować zamknięcie. Funkcja anonimowa jest również określana jako literał funkcji.
Składnia:
func(parameter-list)(returntype){
// code
// Use the return statement if returntype are
given
// if returntype is not given, then do not
// use the return statement
return
}()
Przykład:
// Program to illustrate how
// to create anonymous function
package main
import "fmt"
func main() {
// the anonymous function
func(){
fmt.Println("Welcome to World")
}()
}
Ważne notatki:
o Anonimową funkcję można przypisać do zmiennej w języku programowania Go. Kiedy przypisujemy funkcję do zmiennej, typ zmiennej zmienia się na funkcję i możemy to nazwać wywołaniem funkcji, jak pokazano w poniższym przykładzie:
// Program to illustrate
// the use of an anonymous function
package main
import "fmt"
func main() {
// Assigning anonymous
// function to variable
value := func(){
fmt.Println("Welcome to World")
}
value()
}
o W funkcji anonimowej możemy również przekazywać parametry.
Przykład:
// Program to pass arguments
// in anonymous function
package main
import "fmt"func main() {
// Passing arguments in the anonymous function
func(ele string){
fmt.Println(ele)
}("Helloeveryone")
}
o Funkcja anonimowa może również zostać przekazana jako argument do innej funkcji.
Przykład:
// Program to pass an anonymous
// function as an argument into
// the other function
package main
import "fmt"
// Passing anonymous function
// as argument
func XYZ(i func(a, b string)string){
fmt.Println(i ("Hello", "for"))
}
func main() {
value:= func(a, b string) string{
return a + b + "Hello"
}
XYZ(value)
}
o Inna funkcja może również zwrócić funkcję anonimową.
Przykład:
// Program to illustrate
// the use of anonymous function
package main
import "fmt"
// Returning the anonymous function
func XYZ() func(a, b string) string{
myf := func(a, b string)string{
return a + b + "Everyone"
} return myf
}func main() {
value := XYZ()
fmt.Println(value("Hello ", "to "))
}
Funkcje GoLang main() i init().
Język programowania Go rezerwuje dwie funkcje do celów specjalnych:
main() i init().
Funkcja main()
Główny pakiet w Go to specjalny pakiet używany z aplikacjami wykonywalnymi, w tym z metodą main(). Funkcja main() jest unikalną funkcją, która służy jako punkt wejścia programu wykonywalnego. Nie przyjmuje ani nie zwraca żadnych argumentów. Go wywołuje metodę main() automatycznie, więc nie ma potrzeby jej bezpośredniego wywoływania, a każdy program wykonywalny musi mieć jeden pakiet główny i funkcję main().
Przykład:
// Program to illustrate
// the concept of main() function
// Declaration of main package
package main
// Importing packages
import (
"fmt"
"sort"
"strings"
"time"
)
// Main function
func main() {
// Sorting the given slice
st := []int{335, 79, 113, 14, 86, 12, 467, 9}
sort.Ints(st)
fmt.Println("Sorted slice: ", st)
// Finding the index
fmt.Println("Index value: ", strings.
Index("Hello", "ks"))
// Finding the time
fmt.Println("Time: ", time.Now().Unix())
}
Funkcja init()
Funkcja init(), podobnie jak funkcja main, nie przyjmuje żadnych argumentów i nic nie zwraca. Ta funkcja jest zawarta w każdym pakiecie i jest wywoływana, gdy pakiet jest ładowany po raz pierwszy. Ta funkcja jest zdefiniowana niejawnie, więc nie możemy uzyskać do niej dostępu w innym miejscu. Możemy skonstruować wiele funkcji init() w tej samej aplikacji i będą one wykonywane w kolejności, w jakiej zostały utworzone. Funkcje init() mogą być umieszczone w dowolnym miejscu programu i są wywoływane w leksykalnej kolejności nazw plików (porządek alfabetyczny). Dopuszczalne jest dołączanie instrukcji, jeśli używana jest funkcja init(), ale należy pamiętać, że metoda init() jest wykonywana przed wywołaniem funkcji main(); dlatego nie jest zależny od funkcji main(). Głównym celem funkcji init() jest inicjalizacja zmiennych globalnych, których nie można zainicjować w kontekście globalnym.
Przykład:
// Program to illustrate
// the concept of init() function
// Declaration of main package
package main
// the importing package
import "fmt"
// the multiple init() function
func init() {
fmt.Println("Welcome everyone")
}
func init() {
fmt.Println("Hello everyone ")
}
// the main function
func main() {
fmt.Println("Welcome to home")
}
Co to jest pusty identyfikator (podkreślenie) w GoLang?
W GoLang _(podkreślenie) jest określane jako pusty identyfikator. Identyfikatory to zdefiniowane przez użytkownika nazwy komponentów oprogramowania używane do identyfikacji. GoLang zapewnia funkcję, która pozwala nam zadeklarować i wykorzystać nieużywaną zmienną przy użyciu pustego identyfikatora. Nieużywane zmienne są definiowane przez użytkownika w całym programie, ale nigdy nie są przez niego wykorzystywane. Te zmienne sprawiają, że program jest prawie nieczytelny. Ponieważ GoLang jest bardziej zwięzłym i czytelnym językiem programowania, nie umożliwia programiście określenia niepotrzebnej zmiennej; jeśli to zrobimy, kompilator zgłosi błąd. Gdy funkcja zwraca kilka wartości, ale potrzebujemy tylko kilku z nich, a niektóre odrzucamy, możemy użyć pustego identyfikatora. Informuje kompilator, że ta zmienna nie jest potrzebna i może ją zignorować bez powodowania błędu. Ukrywa wartości zmiennych i czyni program zrozumiałym. W rezultacie za każdym razem, gdy podajemy wartość Identyfikatora banku, staje się on bezużyteczny.
Pierwszy przykład: W poniższym programie funkcja mul_div zwraca dwie wartości, które przechowujemy w identyfikatorach mul i div. Jednak w całym programie używamy tylko jednej zmiennej, mul. W rezultacie kompilator zgłosi błąd, jeśli element div zostanie zadeklarowany, ale nie zostanie wykorzystany.
// Program to show compiler
// throws an error if variable is
// declared but not used
package main
import "fmt"
// the main function
func main() {
// calling function
// function returns two values which are
// assigned to mul and div the identifier
mul, div := mul_div(110, 9)
// only using the mul variable
// compiler will give an error
fmt.Println("110 x 9 = ", mul)
}
// function returning the twov
// values of integer type
func mul_div(nm1 int, nm2 int) (int, int) {
// returning values
return nm1 * nm2, nm1 / nm2
}
Drugi przykład: Aby naprawić powyższy program, użyjmy Blank Identyfikator. Po prostu użyj _(podkreślenia) zamiast identyfikacji elementu div. Pozwala kompilatorowi zignorować zadeklarowany i niewykorzystany błąd dla tej konkretnej zmiennej.
// Program to the use of Blank identifier
package main
import "fmt"
// the main function
func main() {
// calling function
// function returns two values which are
// assigned to mul and blank identifier
mul, _ := mul_div(110, 8)
// only using the mul variable
fmt.Println("110 x 8 = ", mul)
}
// function returning the two
// values of integer type
func mul_div(nm1 int, nm2 int) (int, int) {
// returning the values
return nm1 * nm2, nm1 / nm2
}
Ważne notatki:
o Wiele pustych identyfikatorów może być używanych w tym samym programie. W rezultacie program GoLang może zawierać wiele zmiennych o tej samie nazwie identyfikatora, pusty identyfikator.
o Istnieje wiele sytuacji, w których wartości muszą zostać przypisane tylko po to, aby uzupełnić składnię, mimo że wartości nigdy nie będą wykorzystywane w programie. Jak w funkcji, która zwraca wiele wartości. W takich przypadkach często stosuje się pusty identyfikator.
o W przypadku pustego identyfikatora możemy wykorzystać dowolną wartość dowolnego typu.
SŁOWO KLUCZOWE DEFER
Instrukcje odroczenia w języku Go odkładają wykonanie funkcji lub metody albo metody anonimowej do czasu powrotu pobliskich funkcji. Odroczone parametry wywołania funkcji lub metody, innymi słowy, oceniają natychmiast, ale nie wykonują, dopóki nie powróci pobliska funkcja. Możemy skonstruować opóźnioną metodę, funkcję lub funkcję anonimową za pomocą słowa kluczowego defer.
Składnia:
// Function
defer func func-name(parameterlist Type)
returntype{
// Code
}
// Method
defer func (receiver Type)
methodname(parameterlist){
// Code
}
defer func (parameterlist)(returntype){
// code
}()
Ważne notatki:
o Wiele instrukcji odroczenia jest dozwolonych w tym samym programie w Go i są one wykonywane w sekwencji LIFO (Last-In, First-Out), jak pokazano w drugim przykładzie.
o Parametry instrukcji odroczenia są oceniane w momencie wykonania instrukcji odroczenia, a nie w momencie jej wywołania.
o Instrukcje odroczenia są powszechnie używane w celu zagwarantowania zamknięcia plików, gdy ich użycie nie jest już potrzebne, w celu zamknięcia kanału lub przechwycenia paniki w programie.
Zilustrujmy to pojęcie przykładem:
Pierwszy przykład:
// Program to illustrate
// the concept of the defer statement
package main
import "fmt"
// Functions
func mul(x1, x2 int) int {
rest := x1 * x2
fmt.Println("Result: ", rest)
return 0
}
func show() {
fmt.Println("Hello, Everyone")
}
// the main function
func main() {
// Calling the mul() function
// Here the mul function behaves
// like normal function
mul(43, 25)
// Calling the mul()function
// Using defer keyword
// Here mul() function
// is defer function
defer mul(27, 46)
// Calling show() function
show()
}
Objaśnienie: W powyższym przykładzie istnieją dwie metody o nazwach mul() i show() (). Podczas gdy funkcja show() jest zwykle wywoływana w funkcji main(), funkcja mul() jest wywoływana na dwa sposoby:
Najpierw wywołujemy funkcję mul normalnie (bez słowa kluczowego defer), tj. mul(43, 25), i jest ona wykonywana, gdy funkcja jest wywoływana. Po drugie, używamy słowa kluczowego defer, aby odnieść się do funkcji mul() jako funkcji odroczonej, tj. defer odrocz mul(27, 46) i wykonuje się, gdy wszystkie otaczające metody powrócą.
Drugi przykład:
// Program to illustrate
// the multiple defer statements, to illustrate
LIFO policy
package main
import "fmt"
// Functions
func add(x1, x2 int) int {
rest := x1 + x2
fmt.Println("Result: ", rest)
return 0
}
// the main function
func main() {
fmt.Println("Starting")
// Multiple defer statements
// Executes in the LIFO order
defer fmt.Println("Ending")
defer add(37, 59)
defer add(12, 12)
}
PANIC w GoLang
Panic, podobnie jak wyjątek, pojawia się podczas wykonywania w języku programowania G. Innymi słowy, panika pojawia się, gdy w programie Go wystąpi nieoczekiwana okoliczność, powodująca przerwanie wykonywania programu. Czasami panika pojawia się w czasie wykonywania, gdy pojawia się określony warunek, taki jak dostęp do tablicy poza zakresem, jak pokazano w pierwszym przykładzie, a innym razem jest to celowo rzucane przez programistę, aby obsłużyć najgorszy scenariusz w programie Go za pomocą panika(), jak pokazano w drugim przykładzie. Funkcja paniki jest nieodłączną funkcją zdefiniowaną we wbudowanym pakiecie języka Go. Ta funkcja zatrzymuje przepływ kontroli i zaczyna panikować.
Składnia:
func panic(v interface{})
Jest w stanie zaakceptować każdy rodzaj argumentacji. Gdy w programie Go wystąpi panika, program zatrzymuje się w czasie wykonywania, a na ekranie wyjściowym wyświetlany jest komunikat o błędzie i ślad stosu aż do punktu, w którym wystąpiła panika. Ogólnie rzecz biorąc, kiedy w programie Go pojawia się panika, program nie kończy się natychmiast; zamiast tego kończy się, gdy Go zakończy wszystkie oczekujące prace dla tego programu. Na przykład, jeśli funkcja A wywołuje panikę, wykonywanie funkcji A zostaje zatrzymane, a jeśli w A dostępne są jakieś opóźnione funkcje, działają one normalnie. Następnie funkcja A powraca do swojego wywołującego, a A zachowuje się jak wywołanie paniki do dzwoniącego. Jak widać w trzecim przykładzie, ta procedura jest kontynuowana, dopóki nie zostaną zwrócone wszystkie funkcje w bieżącym goroutine, kiedy to program kończy się niepowodzeniem.
Pierwszy przykład:
// Program which illustrates the
// concept of panic
package main
import "fmt"
// the main function
func main() {
// Creating array of string type
// Using the var keyword
var myarr [3]string
// Elements are assigned using an index
myarr[0] = "HE"
myarr[1] = "Helloeveryone"
myarr[2] = "Hello"
// Accessing elements
// of the array
// Using the index value
fmt.Println("The Elements of Array:")
fmt.Println("The Element 1: ", myarr[0])
// Program panics because the
// size of the array is 3
// we try to access
// the index 5 which is not
// available in current array,
// it gives an runtime error
fmt.Println("The Element 2: ", myarr[5])
}
Drugi przykład:
// Program which illustrates
// how to create own panic
// Using the panic function
package main
import "fmt"
// Function
func entry(lang *string, aname *string) {
// When value of lang
// is nil it will panic
if lang == nil {
panic("Error: The Language cannot be nil")
}
// When value of aname
// is nil it will panic
if aname == nil {
panic("Error: The Author name cannot be
nil")
}
// When values of the lang and aname
// are non-nil values it will print
// the normal output
fmt.Printf("The Author Language: %s \n Author
Name: %s\n", *lang, *aname)
}
// the main function
func main() {
A_lang := "GO-Language"
// Here in the entry function, we pass
// a non-nil, nil values
// Due to nil value this method panics
entry(&A_lang, nil)
}
Trzeci przykład:
// Program which illustrates
// the concept of Defer while panicking
package main
import (
"fmt"
)
// Function
func entry(lang *string, aname *string) {
// the Defer statement
defer fmt.Println("The Defer statement in the
entry function")
// When value of lang
// is nil it will panic
if lang == nil {
panic("Error: The Language cannot be nil")
}
// When value of aname
// is nil it will panic
if aname == nil {
panic("Error: The Author name cannot be
nil")
}
// When values of the lang and aname
// are non-nil values it will
// print the normal output
fmt.Printf("The Author Language: %s \n Author
Name: %s\n", *lang, *aname)
}
// the main function
func main() {
A_lang := "GO-Language"
// the Defer statement
defer fmt.Println("the Defer statement in the
main function")
// in entry function, we pass
// one non-nil and one-nil value
// Due to nil value this method panics
entry(&A_lang, nil)
}
Zauważ, że instrukcja lub funkcja Defer jest wykonywana zawsze, nawet jeśli program panikuje.
Użycie panic<
o Możemy użyć paniki, aby wskazać nienaprawialny błąd, w wyniku którego program nie może kontynuować działania.
o Jeśli chcemy, aby w naszym programie pojawił się błąd w określonych okolicznościach, możemy użyć panic.
ODZYSKIWANIE
Podobnie jak bloki try/catch w językach takich jak Java, C# i inne są używane do przechwytywania wyjątków, funkcja recovery w Go służy do obsługi paniki. Jest to wbudowana funkcja zdefiniowana we wbudowanym pakiecie języka Go. Ta metoda jest używana głównie do odzyskania kontroli nad spanikowanym goroutine. Innymi słowy, zajmuje się panicznym zachowaniem goroutine.
Składnia:
func recover() interface{}
Szybkie punkty
o Funkcja odzyskiwania jest zawsze wywoływana w ramach funkcji opóźnionej, a nigdy w funkcji zwykłej. Używając funkcji odzyskiwania z normalnej funkcji lub poza funkcją opóźnioną, sekwencja paniki jest kontynuowana, jak pokazano w pierwszym przykładzie. Jak pokazano w drugim przykładzie, funkcja odzyskiwania jest zawsze wywoływana wewnątrz funkcji odroczonej, ponieważ funkcja odroczona nie zatrzymuje swojego wykonywania, jeśli program panikuje, więc funkcja odzyskiwania zatrzymuje sekwencję paniki, po prostu przywracając normalne wykonanie goroutine i pobierając przekazaną wartość błędu na panikę.
o Funkcja przywracania będzie działać tylko wtedy, gdy wywołamy ją w tym samym trybie, w którym wystąpiła panika. Nie zadziała tak, jak pokazano w trzecim przykładzie, jeśli wywołamy go w oddzielnej goroutine.
o Jeśli chcemy znaleźć ślad stosu, skorzystajmy z metody PrintStack z pakietu Debug.
Pierwszy przykład:
// Program which illustrates
// the concept of recover
package main
import "fmt"
// This function is created to handle
panic occurs in entry function
// but it does not handle panic
occurred in entry function
// because it called in normal
function
func handlepanic() {
if a := recover(); a != nil {
fmt.Println("RECOVER", a)
}
}
// Function
func entry(lang *string, aname *string) {
// Normal function
handlepanic()
// When value of lang
// is nil it will panic
if lang == nil {
panic("Error: Language cannot be nil")
}
// When value of aname
// is nil it will panic
if aname == nil {
panic("Error: Author name cannot be nil")
}
fmt.Printf("The Author Language: %s \n Author
Name: %s\n", *lang, *aname)
fmt.Printf("Return successfully from entry
function")
}
// The main function
func main() {
A_lang := "GO Language"
entry(&A_lang, nil)
fmt.Printf("Return successfully from the main
function")
}
ZAMKNIĘCIE
Funkcja anonimowa jest cechą języka programowania Go. Anonimowa funkcja może stanowić zamknięcie. Zamknięcie jest rodzajem anonimowej funkcji, która odwołuje się do zmiennych określonych poza funkcją. Jest to analogiczne do dostępu do zmiennych globalnych dostępnych przed deklaracją funkcji.
Przykład:
// Program to illustrate how
// to create Closure
package main
import "fmt"
func main() {
// Declaring variable
HFW := 0
// Assigning an anonymous
// function to variable
counter := func() int {
HFW += 1
return HFW
}
fmt.Println(counter())
fmt.Println(counter())
}
Objaśnienie: Zmienna HFW nie została przekazana jako argument funkcji anonimowej, ale jest dostępna dla tej funkcji. Ten przykład ma niewielki problem, ponieważ każda inna funkcja określona w main musi mieć dostęp do zmiennej globalnej HFW i może ją aktualizować bez wywoływania funkcji licznika. W rezultacie zamknięcie zapewnia również inną korzyść: izolację danych.
// Program to illustrate how
// to create the data isolation
package main
import "fmt"
// newCounter function to
// isolate the global variable
func newCounter() func() int {
HFW := 0
return func() int {
HFW += 1
return HFW
}
}
func main() {
// newCounter function is assigned to a
variable
counter := newCounter()
// invoke the counter
fmt.Println(counter())
// invoke the counter
fmt.Println(counter())
}
Objaśnienie: Zamknięcie odwołuje się do zmiennej HFW nawet po zakończeniu funkcji newCounter(), ale żaden inny kod poza metodą newCounter() nie ma do niej dostępu. W ten sposób utrzymywana jest trwałość danych w wywołaniach funkcji, jednocześnie izolując dane z innych programów.
REKURENCJA
Rekurencja to proces, w którym funkcja wywołuje samą siebie, niejawnie lub jawnie, a powiązana funkcja jest znana jako funkcja rekurencyjna. Funkcja anonimowa jest szczególną cechą języka programowania Go. Jest to funkcja, która nie ma nazwy. Służy do tworzenia funkcji wbudowanej. Można również określić i zdefiniować anonimowe funkcje rekurencyjne. Rekurencyjne funkcje anonimowe są również określane jako literały funkcji rekurencyjnych.
Składnia
func(parameterlist)(returntype){
// code
// call the same function
// within function for recursion
// Use the return statement only
// if return-type are given.
return
}()
Pierwszy przykład :
// Program to show
// how to create recursive
// Anonymous function
package main
import "fmt"
func main() {
// Anonymous function
var recursiveAnonymous func()
recursiveAnonymous = func() {
// Printing message to show
// the function call and iteration.
fmt.Println("The Anonymous functions could
be recursive.")
// Calling the same function
recursively
recursiveAnonymous()
}
// the main calling of function
recursiveAnonymous()
}
Drugi przykład:
// Program to show
// how to create recursive
// Anonymous function
package main
import (
"fmt"
)
func main() {
// the Anonymous function
var recursiveAnonymous func(int)
// Passing arguments to Anonymous function
recursiveAnonymous = func(variable int) {
// Checking condition to return
if variable == -1 {
fmt.Println("Welcome to our Channel")
return
} else {
fmt.Println(variable)
// Calling the same
// function recursively
recursiveAnonymous(variable - 1)
}
}
// the main calling
// of function
recursiveAnonymous(10)
}
Typy rekurencji
Istnieje kilka odmian rekurencji, co ilustrują poniższe przykłady.
Bezpośrednia rekurencja
Rekurencja bezpośrednia to rodzaj rekurencji, w której funkcja wywołuje samą siebie bezpośrednio, bez pomocy innej funkcji. Poniższy przykład ilustruje koncepcję bezpośredniej rekurencji:
// Program to illustrate
// the concept of direct recursion
package main
import (
"fmt"
)
// the recursive function for
// calculating factorial of a positive integer
func factorial_calc(number int) int {
// this is base condition
// if number is 0 or 1 the function will return 1
if number == 0 || number == 1 {
return 1
}
// if the negative argument is
// given, it prints error message & returns -1
if number < 0 {
fmt.Println("Invalid-number")
return -1
}
// the recursive call to itself with argument
decremented
// by 1 integer so that it
// eventually reaches base case
return number*factorial_calc(number - 1)
}
// main function
func main() {
// passing 0 as a parameter
answer1 := factorial_calc(0)
fmt.Println(answer1, "\n")
// passing a positive integer
answer2 := factorial_calc(5)
fmt.Println(answer2, "\n")
// passing negative integer
// prints error message
// with return value of -1
answer3 := factorial_calc(-1)
fmt.Println(answer3, "\n")
// passing positive integer
answer4 := factorial_calc(10)
fmt.Println(answer4, "\n")
}
Rekurencja pośrednia
Rekurencja pośrednia to rodzaj rekurencji, w której funkcja wywołuje inną funkcję, która następnie wywołuje funkcję wywołującą. Inna funkcja służy do wspomagania tej formy rekurencji. Funkcja wywołuje samą siebie, ale robi to pośrednio za pośrednictwem innej funkcji. Poniższy przykład ilustruje koncepcję rekurencji pośredniej:
// Program to illustrate
// the concept of indirect recursion
package main
import (
"fmt"
)
// the recursive function for printing all numbers
// upto number x
func print_one(x int) {
// if number is positive
// print the number
// call second function
if x >= 0 {
fmt.Println("In first function:", x)
// call to the second function
// which calls this first
// function indirectly
print_two(x - 1)
}
}
func print_two(x int) {
// if number is positive
// print the number, call second function
if x >= 0 {
fmt.Println("In second function:", x)
// call to first function
print_one(x - 1)
}
}
// main function
func main() {
// passing positive
// parameter which prints all
// the numbers from 1 - 10
print_one(10)
// this will not print anything as it does not
// follow base case
print_one(-1)
}
Uwaga: Rekurencja wzajemna odnosi się do rekurencji pośredniej z tylko dwiema funkcjami. Aby wspomóc rekurencję pośrednią, może istnieć więcej niż dwie funkcje.
Rekurencja ogona
Wywołanie ogona to wywołanie podprogramu, które jest ostatnim lub ostatnim wywołaniem funkcji. Kiedy wywołanie ogona ponownie wywołuje tę samą funkcję, mówi się, że funkcja jest rekurencyjna ogona. Wywołanie rekurencyjne jest ostatnią czynnością wykonywaną przez funkcję w tym przypadku.
Przykład:
// Program to illustrate
// the concept of tail recursion
package main
import (
"fmt"
)
// the tail recursive function
// to print all the numbers
// from x to 1
func print_num(x int) {
// if number is still
// positive, print it
// and call the function
// with decremented value
if x > 0 {
fmt.Println(x)
// last statement in
// the recursive function
// tail recursive call
print_num(x-1)
}
}
// the main function
func main() {
// passing positive
// number, prints 5 to 1
print_num(5)
}
Rekurencja głowy
Wywołanie rekurencyjne jest początkową instrukcją w funkcji w rekurencji głowy. Nie ma żadnych dalszych instrukcji ani operacji poprzedzających wywołanie. Funkcja nie musi niczego przetwarzać po wywołaniu, a wszystkie operacje są zakończone po powrocie.
Przykład:
// Program to illustrate
// the concept of head recursion
package main
import (
"fmt"
)
// the head recursive function
// to print all the numbers
// from 1 to x
func print_num(x int) {
// if the number is still
// less than x, call
// function with decremented value
if x > 0 {
// the first statement in function
print_num(x-1)
// printing is done at
// the returning time
fmt.Println(x)
}
}
// the main function
func main() {
// passing positive
// number, prints 5 to 1
print_num(5)
}
Uwaga: Warto zauważyć, że wynik rekurencji głowy jest dokładnie odwrotny do wyniku rekurencji ogona. Dzieje się tak dlatego, że w rekurencji ogonowej funkcja najpierw wypisuje liczbę, a następnie wywołuje samą siebie, ale w rekurencji czołowej funkcja wywołuje samą siebie, dopóki nie osiągnie przypadku podstawowego, a następnie rozpoczyna drukowanie podczas powrotu.
Nieskończona rekurencja
Wszystkie funkcje rekurencyjne były określonymi lub skończonymi funkcjami rekurencyjnymi, co oznacza, że kończyły się, gdy osiągnęły warunek podstawowy. Rekurencja nieskończona to rekurencja, która nigdy nie jest zbieżna do przypadku podstawowego i trwa w nieskończoność. To często prowadzi do awarii systemu lub wycieków pamięci.
Przykład:
// Program to illustrate
// the concept of infinite recursion
package main
import (
"fmt"
)
// infinite-recursion function
func print_hello() {
// printing infinite-times
fmt.Println("Helloeveryone")
print_hello()
}
// the main function
func main() {
// call to infinite recursive-function
print_hello()
}
Rekurencja funkcji anonimowej
W GoLang istnieje koncepcja znana jako funkcje, które nie mają nazwy. Są to tak zwane funkcje anonimowe. Anonimowe funkcje w GoLang mogą być również używane do rekurencji, jak widać w poniższych przykładach.
Pierwszy przykład:
// Program to illustrate
// the concept of anonymous function recursion
package main
import (
"fmt"
)
// main function
func main() {
// declaring anonymous function
// that takes integer value
var anon_func func(int)
// defining the anonymous
// function that prints the numbers from x to 1
anon_func = func(number int) {
// the base case
if number == 0 {
return
} else {
fmt.Println(number)
// calling anonymous function
recursively
anon_func(number-1)
}
}
// call to anonymous recursive function
anon_func(5)
}
Drugi przykład:
// Program which illustrates the
// concept of recover
package main
import (
"fmt"
)
// This function handles panic
// occur in the entry function
// with help of the recover function
func handlepanic() {
if x := recover(); x != nil {
fmt.Println("RECOVER", x)
}
}
// Function
func entry(lang *string, aname *string) {
// the Deferred function
defer handlepanic()
// When value of lang is nil it will panic
if lang == nil {
panic("Error: The Language cannot be nil")
}
// When value of aname
// is nil it will panic
if aname == nil {
panic("Error: The Author name cannot be
nil")
}
fmt.Printf("The Author Language: %s \n Author
Name: %s\n", *lang, *aname)
fmt.Printf("The Return successfully from entry
function")
}
// the main function
func main() {
A_lang := "GO-Language"
entry(&A_lang, nil)
fmt.Printf("The Return successfully from main
function")
}
Trzeci przykład
// Program which illustrates
// the recover in a goroutine
package main
import (
"fmt"
"time"
)
// For the recovery
func handlepanic() {
if x := recover(); x != nil {
fmt.Println("RECOVER", x)
}
}
/* Here, this panic is not handled by recover
function because of recover function is not
called in the same goroutine in which
panic occurs */
// the Function 1
func myfun1() {
defer handlepanic()
fmt.Println("Welcome to the Function1")
go myfun2()
time.Sleep(10 * time.Second)
}
// the Function 2
func myfun2() {
fmt.Println("Welcome to Function2")
panic("Panicked!!")
}
// the main function
func main() {
myfun1()
fmt.Println("The Return successfully from main
function")
}
GoLang X
Współbieżność i Goroutines
GOROUTINES - WSPÓŁBIEŻNOŚĆ W GoLang
Goroutine to szczególna cecha języka programowania Go. Goroutine to funkcja lub metoda, która działa niezależnie i równolegle z innymi Goroutine w naszym programie. Innymi słowy, każda stale wykonywana akcja w języku programowania Go jest określana jako Goroutine. Goroutine można traktować jako lekką nić. W porównaniu z nicią koszt założenia Goroutines jest dość niski. Każdy program zawiera co najmniej jeden Goroutine, który jest określany jako główny Goroutine. Wszystkie Goroutines są podporządkowane głównym Goroutines; jeśli główna goroutine zakończy się, wszystkie goroutines w programie zakończą się. Goroutine zawsze działa w tle. Współbieżność poprawia wydajność dzięki wykorzystaniu wielu rdzeni przetwarzających. Obsługa API Go umożliwia programistom wydajną implementację algorytmów równoległych. Obsługa współbieżności jest opcjonalną funkcją większości głównych języków programowania; jest jednak wbudowany w Go.
Przejdź do programowania współbieżnego
Programowanie współbieżne w pełni wykorzystuje liczne rdzenie procesorów występujące w większości współczesnych systemów. Pojęcie to istnieje od dawna, nawet gdy pojedynczy rdzeń miał tylko jeden rdzeń. Używanie kilku wątków do tworzenia jakiejś formy współbieżności było szeroko rozpowszechnionym podejściem w wielu językach programowania, w tym C/C++, Java i innych. Pojedynczy wątek to zasadniczo mały zestaw instrukcji zaplanowanych do wykonania indywidualnie. Możemy myśleć o tym jako o małym zadaniu w ramach większego projektu. W rezultacie wiele wątków wykonawczych jest łączonych i uruchamianych równolegle w celu wykonania skomplikowanego procesu. Ta spójność na wielu stanowiskach daje wrażenie równoczesnej realizacji. Należy jednak pamiętać, że dowolny ograniczony sprzęt - taki jak pojedynczy procesor - może osiągnąć tylko określoną liczbę zadań, planując działania z podziałem czasu. Dzisiejsze urządzenia komputerowe zasilane są przez wiele rdzeni. W rezultacie język, który potrafi w pełni wykorzystać swój potencjał, jest stale poszukiwany. Główne języki programowania stopniowo uznają tę prawdę i próbują włączyć współbieżność do swoich podstawowych możliwości. Jednak twórcy Go rozumowali: "Dlaczego nie zbudować języka od podstaw z koncepcją współbieżności jako jedną z jego podstawowych cech?" Jeden z takich języków, który zapewnia interfejsy API wysokiego poziomu do pisania współbieżnych programów w Go.
Problemy z wielowątkowością
Aplikacje wielowątkowe są trudne nie tylko do tworzenia i utrzymywania, ale także do debugowania. Ponadto rozbicie dowolnego procesu przy użyciu kilku wątków nie zawsze jest możliwe, aby uczynić go tak wydajnym, jak programowanie współbieżne. Wielowątkowość ma swój własny zestaw kosztów. Środowisko obsługuje wiele zadań, w tym komunikację między procesami i dostęp do pamięci współdzielonej. Deweloperzy mogą skoncentrować się na wykonywanym zadaniu, zamiast wikłać się w szczegóły przetwarzania równoległego. Pamiętając o tych kwestiach, inną opcją jest całkowite poleganie na systemie operacyjnym w zakresie przetwarzania wieloprocesowego. W tym przypadku zadaniem programisty jest radzenie sobie ze złożonością komunikacji międzyprocesowej lub kosztem współbieżności pamięci współdzielonej. Strategię tę można bardzo modyfikować na korzyść wydajności, ale łatwo ją też zepsuć.
Programowanie współbieżne w Go
Go zapewnia potrójne rozwiązanie do programowania współbieżnego.
o Wsparcie na wysokim poziomie sprawia, że współbieżność jest nie tylko łatwiejsza do wdrożenia, ale także łatwiejsza w zarządzaniu.
o Stosowane są goroutines. Nici są cięższe niż gorutyny.
o Bez interwencji programistów zautomatyzowane wyrzucanie elementów bezużytecznych w Go rozwiązuje złożoność zarządzania pamięcią.
Jak radzić sobie z problemami współbieżności w Go
Goroutines ułatwiają budowanie współbieżności i podstawowych prymitywów. Czynność wykonująca jest w tym kontekście określana jako goroutine. Rozważmy program mający dwie funkcje, które nie komunikują się ze sobą. W wykonywaniu sekwencyjnym jedna funkcja kończy swoje wykonanie przed wywołaniem innej. Jednak w Go funkcja może być jednocześnie aktywna i wykonywana. Jest to proste, jeśli funkcje są niepołączone, ale mogą wystąpić komplikacje, gdy są one ze sobą połączone i mają ten sam czas trwania wykonywania. Nawet przy wysokim poziomie obsługi współbieżności w Go, problemów tych nie da się całkowicie uniknąć, zwłaszcza jeśli główna funkcja zakończy swoje wykonanie przed funkcjami, które na niej polegają. W rezultacie musimy być ostrożni, aby główny goroutine czekał, aż wszystkie zadania zostaną wykonane. Innym problemem jest zakleszczenie, które występuje, gdy więcej niż jeden goroutine blokuje określony zasób, aby zachować wyłączność, podczas gdy inny próbuje uzyskać ten sam zamek w tym samym czasie. Tego rodzaju niebezpieczeństwo jest typowe dla programowania współbieżnego, ale Go zawiera poprawkę, która eliminuje potrzebę blokad dzięki wykorzystaniu kanałów. Po zakończeniu zadania często tworzony jest kanał powiadamiający o zakończeniu wykonywania. Inną opcją jest użycie synchronizacji do oczekiwania na raport. Grupa oczekiwania. Jednak zakleszczenie może nadal wystąpić w dowolnym przypadku i co najwyżej można mu zapobiec dzięki starannemu projektowi. Go po prostu oferuje narzędzia do planowania prawidłowego działania współbieżności
Goroutine z WaitGroup Przykład
Możemy ustanowić goroutine, poprzedzając dowolne wywołanie funkcji terminem go. Następnie funkcja działa jak wątek, konstruując goroutine zawierającą ramkę wywołania i planując jej działanie jako wątek. Może uzyskiwać dostęp do dowolnych argumentów, globali lub czegokolwiek dostępnego w jego zasięgu, tak jak każda inna funkcja. Oto podstawowy kod, którego można użyć do określenia, czy witryna działa, czy nie. Identyczny kod jest następnie stosowany do goroutine. Zanotuj, jak zwiększa się szybkość wykonywania, gdy używamy współbieżności.
package main
import (
"fmt"
"net/http"
"time"
)
func main() {
start := time.Now()
sitelist := []string{
"https://www.google.com//",
"https://www.youtube.com/",
"https://www.pinterest.com/",
"https://www.codeguru.com/",
"https://www.nasa.gov/",
}
for _, site := range sitelist {
GetSiteStatus(site)
}
fmt.Printf("\n\nTime elapsed since %v\n\n", time.
Since(start))
}
func GetSiteStatus(site string) {
if _, err := http.Get(site); err != nil {
fmt.Printf("%s is down\n", site)
} else {
fmt.Printf("%s is up\n", site)
}
}
Jak stworzyć Goroutine
Możemy po prostu stworzyć własną Goroutine, poprzedzając wywołanie funkcji lub metody słowem kluczowym go, jak widać w następującej składni:
Składnia:
func name(){
// statement
}
// using go keyword as
// the prefix of our function call
go name()
Przykład:
// Program to illustrate the
// concept of Goroutine
package main
import "fmt"
func display(str string) {
for c := 0; c < 5; c++ {
fmt.Println(str)
}
}
func main() {
// Calling the Goroutine
go display("Welcome")
// Calling the normal function
display("Helloeveryone")
}
W powyższym przykładzie definiujemy metodę display() i wywołujemy ją na dwa różne sposoby. Pierwsza to Goroutine, taka jak go display("Witamy"), a druga to normalna funkcja, taka jak display("Helloeveryone"). Jest jednak problem: pokazuje tylko wynik normalnej funkcji, a nie wynik Goroutine, ponieważ kiedy wywoływany jest nowy Goroutine, Goroutine natychmiast wywołuje zwroty. Kontrolka nie czeka, aż Goroutine zakończy wykonywanie; zamiast tego przechodzi do następnego wiersza po wywołaniu Goroutine i ignoruje wartość podaną przez Goroutine. Tak więc, aby poprawnie uruchomić Goroutine, wprowadziliśmy następujące zmiany w naszym programie:
Zaktualizowany przykład:
// program to illustrate concept of Goroutine
package main
import (
"fmt"
"time"
)
func display(str string) {
for w := 0; w < 5; w++ {
time.Sleep(1 * time.Second)
fmt.Println(str)
}
}
func main() {
// Calling Goroutine
go display("Hello")
// Calling the normal function
display("Helloeveryone")
}
W naszej aplikacji wprowadziliśmy funkcję Sleep(), która powoduje uśpienie głównego Goroutine na 1 sekundę pomiędzy 1 sekundą wykonania nowego Goroutine, wyświetleniem "Hello" na ekranie, a następnie zakończeniem po 1 sekundzie głównego Goroutine zmienia harmonogram i wykonuje swoje działania. Ta procedura jest kontynuowana aż do osiągnięcia wartości z<5, w którym to momencie główny Goroutine się kończy. W takim przypadku zarówno Goroutine, jak i normalna funkcja są w stanie działać wydajnie. Goroutines zapewniają następujące korzyści:
o Goroutines są tańsze niż wątki.
o Goroutines są przechowywane na stosie, a rozmiar stosu może się zwiększać i zmniejszać w zależności od potrzeb programu. Jednak rozmiar stosu w wątkach jest stały.
o Goroutines mogą wchodzić w interakcje przez kanał, a kanały te mają na celu zapobieganie problemom związanym z wyścigiem podczas korzystania z Goroutines w celu uzyskania dostępu do pamięci współdzielonej.
o Załóżmy, że program ma pojedynczy wątek z dołączonymi do niego kilkoma Goroutines. Jeśli którykolwiek z Goroutines zablokuje wątek z powodu ograniczeń zasobów, wszystkie pozostałe Goroutines zostaną przypisane do nowo wygenerowanego wątku systemu operacyjnego. Programiści nie są świadomi żadnej z tych informacji.
Anonimowe Goroutines
W Go możemy uruchomić Goroutine dla anonimowej funkcji, lub innymi słowy, możemy skonstruować anonimowy Goroutine po prostu używając słowa kluczowego go jako przedrostka tej funkcji, jak widać w następującej składni:
Składnia:
// the Anonymous function call
go func (parameterlist){
// statement..
}(arguments)
Przykład:
// Program to illustrate how
// to create anonymous Goroutine
package main
import (
"fmt"
"time"
)
// the main function
func main() {
fmt.Println("Welcome to the main function")
// Creating the Anonymous Goroutine
go func() {
fmt.Println("Welcome to ourworld")
}()
time.Sleep(1 * time.Second)
fmt.Println("GoodBye ")
}
INSTRUKCJA SELECT
Instrukcja select w Go jest podobna do instrukcji switch; jednakże instrukcja case w instrukcji select odnosi się do komunikacji, tj. operacji wysyłania lub odbierania na kanale.
Składnia:
select{
case SendOrReceive1: // Statement..
case SendOrReceive2: // Statement..
case SendOrReceive3: // Statement..
.
.
default: // Statement..
Należy wziąć pod uwagę:
o W pewnych okolicznościach instrukcja select czeka, aż komunikacja (operacja wysyłania lub odbierania) będzie gotowa przed kontynuowaniem.
Przykład:
// Program to illustrate
// the concept of select statement
package main
import("fmt"
"time")
// function 1
func portal1(channel1 chan string) {
time.Sleep(3*time.Second)
channel1 <- "Welcome to channel1"
}
// function 2
func portal2(channel2 chan string) {
time.Sleep(9*time.Second)
channel2 <- "Welcome to channel2"
}
// the main function
func main(){
// Creating the channels
R1:= make(chan string)
R2:= make(chan string)
// calling function 1
// and function 2 in the goroutine
go portal1(R1)
go portal2(R2)
select{
// case 1 for portal1
case op1:= <- R1:
fmt.Println(op1)
// case 2 for portal2
case op2:= <- R2:
fmt.Println(op2)
}
}
Objaśnienie: W poprzednim programie portal1 był uśpiony przez 3 sekundy, a portal2 był uśpiony przez 9 sekund przed uruchomieniem. Teraz instrukcja select czeka, aż skończy się ich czas uśpienia, a następnie wybiera przypadek 2 i wyświetla komunikat "Witamy na kanale 1". Jeśli portal 1 obudzi się przed portalem 2, wyjściem będzie "witamy w kanale 2".
o Jeśli instrukcja select nie zawiera instrukcji case, będzie czekać w sposób nieokreślony.
Składnia:
select{}
Przykład:
// Program to illustrate
// the concept of select statement
package main
// the main function
func main() {
// Select statement without any case
select{ }
}
o Domyślna instrukcja select służy do zapobiegania blokowaniu instrukcji select. Ta instrukcja jest wykonywana, gdy nie ma instrukcji case, a instrukcja jest gotowa do kontynuacji.
Przykład:
// Program to illustrate
// the concept of select statement
package main
import "fmt"
// the main function
func main() {
// the creating channel
mychannel:= make(chan int)
select{
case <- mychannel:
default:fmt.Println("Not-found")
}
}
o Gdy żadna instrukcja case nie jest gotowa, a instrukcja select nie zawiera żadnych instrukcji domyślnych, instrukcja select zostanie zablokowana, dopóki co najmniej jedna instrukcja case lub komunikacja nie będą mogły być kontynuowane.
Przykład:
// Program to illustrate
// the concept of select statement
package main
// the main function
func main() {
// creating the channel
mychannel:= make(chan int)
// channel is not ready and
// no default case
select{
case <- mychannel:
}
}
o Jeśli wiele przypadków jest gotowych do kontynuowania, można wybrać losowo w instrukcji select.
Przykład:
// Program to illustrate
// the concept of select statement
package main
import "fmt"
// function 1
func portal1(channel1 chan string){
for i := 0; i <= 4; i++{
channel1 <- "Welcome to channel1"
}
}
// function 2
func portal2(channel2 chan string){
channel2 <- "Welcome to channel2"
}
// the main function
func main() {
// Creating the channels
R1:= make(chan string)
R2:= make(chan string)
// calling the function 1 and function 2 in
goroutine
go portal1(R1)
go portal2(R2)
// the choice of selection of case is random
select{
case op1:= <- R1:
fmt.Println(op1)
case op2:= <- R2:
fmt.Println(op2)
}
}
WIELE GOROUTINE
Goroutine to funkcja lub metoda w naszym programie, która działa niezależnie i równolegle z innymi Goroutine. Innymi słowy, każda współbieżnie wykonywana akcja w języku programowania Go jest określana jako Goroutine. Możemy mieć kilka gorutyn w jednym programie w języku programowania Go. Możemy łatwo skonstruować goroutine, poprzedzając wywołanie funkcji lub metody słowem kluczowym go, jak ilustruje to następująca składnia:
func name(){
// statement(s)
}
// using go keyword as
// the prefix of your function call
go name()
Za pomocą przykładu zbadamy teraz, jak utworzyć i pracować nad kilkoma goroutines:
// Program to illustrate the Multiple Goroutines
package main
import (
"fmt"
"time"
)
// For goroutine 1
func Aname() {
arr1 := [4]string{"Ronik", "Sunita", "Arman",
"Tia"}
for tk1 := 0; tk1 <= 3; tk1++ {
time.Sleep(150 * time.Millisecond)
fmt.Printf("%s\n", arr1[tk1])
}
}
// For goroutine 2
func Aid() {
arr2 := [4]int{400, 201, 402, 203}
for tk2 := 0; tk2 <= 3; tk2++ {
time.Sleep(500 * time.Millisecond)
fmt.Printf("%d\n", arr2[tk2])
}
}
// the main function
func main() {
fmt.Println("!The Main Go-routine Start!")
// calling Goroutine 1
go Aname()
// calling Goroutine 2
go Aid()
time.Sleep(2900 * time.Millisecond)
fmt.Println("\n! The Main Go-routine End!")
}
1. Tworzenie: Z powyższego przykładu mamy dwie goroutine i główną goroutine, czyli Aname i Aid. Tutaj Aname drukuje nazwiska autorów, a Aid drukuje identyfikator autorów.
2. Praca: Mamy tutaj dwie goroutines, Aname i Aid, oraz jedną główną goroutine. Kiedy uruchamiamy ten program, startuje główna procedura goroutine i wypisuje "!Main Go-routine Start!" Ponieważ główny goroutine jest jak rodzic, a inne goroutines są jego dziećmi, główny goroutine działa jako pierwszy, a następnie inne goroutines, a jeśli główny goroutine się kończy, inne goroutines również się kończą. W rezultacie, po głównym goroutine, goroutines Aname i Aid zaczynają działać równolegle
KANAŁ GoLang
Kanał w Go to medium, za pośrednictwem którego goroutine komunikuje się z innym goroutine w sposób wolny od blokad. Innymi słowy, kanał jest mechanizmem, który pozwala jednemu gorutynowi przesyłać dane do drugiego. Kanał jest domyślnie dwukierunkowy, co oznacza, że gorutyny mogą przesyłać i odbierać dane tym samym kanałem, jak pokazano na poniższym rysunku.
Tworzenie kanału
Kanał jest tworzony w Go za pomocą słowa kluczowego chan i może przesyłać tylko dane tego samego rodzaju; z tego samego kanału nie można przesyłać wielu typów danych.
Składnia:
var Channelname chan Type
Możemy również użyć skróconej deklaracji do zbudowania kanału z metodą make().
Składnia:
channelname:= make(chan Type)
Przykład:
// Program to illustrate
// how to create channel
package main
import "fmt"
func main() {
// Creating channel
// Using the var keyword
var mychannel chan int
fmt.Println("The Value of the channel: ",
mychannel)
fmt.Printf("The Type of the channel: %T ",
mychannel)
// Creating channel using the make() function
mychannel1 := make(chan int)
fmt.Println("\nThe Value of the channel1: ",
mychannel1)
fmt.Printf("The Type of the channel1: %T ",
mychannel1)
}
Wysyłaj i odbieraj dane z kanału
W języku programowania Go kanały wykonują dwie podstawowe operacje: wysyłanie i odbieranie, zwane łącznie komunikacją. A to, czy dane są odbierane, czy wysyłane, jest wskazywane przez kierunek operatora <-. Domyślnie operacje wysyłania i odbierania w kanale są blokowane, dopóki druga strona nie będzie gotowa. Umożliwia gorutynom komunikowanie się ze sobą bez wyraźnych blokad lub zmiennych warunków.
Operacja wysyłania
Operacja wysyłania wysyła dane z jednej gorutyny do drugiej przez kanał. Wartości, takie jak int, float64 i bool, są bezpieczne i proste do przesłania przez kanał, ponieważ są kopiowane, co eliminuje możliwość przypadkowego równoczesnego dostępu do tej samej wartości. Łańcuchy są podobnie bezpieczne do przesyłania, ponieważ są niezmienne. Jednak przesyłanie wskaźników lub odniesień, takich jak wycinek, mapa itp., przez kanał nie jest bezpieczne, ponieważ wartość wskaźników lub odniesień może ulec zmianie podczas wysyłania lub odbierania gorutyny w tym samym czasie, co skutkuje nieprzewidywalnymi konsekwencjami. W rezultacie, używając wskaźników lub odwołań w kanale, musimy upewnić się, że mogą one uzyskać dostęp tylko przez jedną goroutine na raz.
Mój kanał <- element
Powyższe zdanie wskazuje, że dane (element) zostały przesłane do kanału (Mój kanał) za pomocą operatora <-.
Operacja odbioru
Operacja odbierania służy do odbierania danych wysłanych przez operatora wysyłania.
element := <-Mój kanał
Zgodnie z powyższym zdaniem element pobiera dane z kanału (Mychannel). Jeżeli wynik otrzymanego oświadczenia nie będzie wykorzystany, oświadczenie jest również ważne. Instrukcję odbioru można alternatywnie zapisać jako:
<-Mój kanał
Przykład:
// Program to illustrate send and
// receive operation
package main
import "fmt"
func myfunc(ch chan int) {
fmt.Println(234 + <-ch)
}
func main() {
fmt.Println("Main method start")
// Creating channel
ch := make(chan int)
go myfunc(ch)
ch <- 23
fmt.Println("Main method end")
}
Zamknięcie kanału
Możemy również użyć metody close() do zamknięcia kanału. Ta wbudowana funkcja ustawia flagę wskazującą, że żadne dodatkowe dane nie będą wysyłane do tego kanału.
close()
Możemy również użyć pętli for range, aby zamknąć kanał. Goroutine odbiornika może użyć następującej składni, aby określić, czy kanał jest otwarty, czy zamknięty:
Składnia:
ele, ok:= <- Mój kanał
Jeśli wartość ok jest równa true, oznacza to, że kanał jest otwarty i można wykonywać operacje odczytu. A jeśli wartość jest fałszywa, oznacza to, że kanał jest zamknięty; w związku z tym operacje odczytu zakończą się niepowodzeniem.
Przykład:
// program to illustrate
// how to close channel using
// for range loop and close function
package main
import "fmt"
// Function
func myfun(mychnl chan string) {
for k := 0; k < 4; k++ {
mychnl <- "Helloeveryone"
}
close(mychnl)
}
// the main function
func main() {
// Creating channel
ch := make(chan string)
// calling Goroutine
go myfun(ch)
// When value of ok is
// set to true means
// channel is open and
// it can send or receive data
// When value of ok is set to
// false means channel is closed
for {
rest, ok := <-c
if ok == false {
fmt.Println("Channel-Close ", ok)
break
}
fmt.Println("Channel-Open ", rest, ok)
}
}
Ważne notatki:
o Blokowanie wysyłania i odbierania: Kiedy dane są przesyłane do kanału, sterowanie jest blokowane w tej instrukcji wysyłania, dopóki inna goroutine nie odczyta tego kanału. Podobnie, gdy kanał pobiera dane z goroutine, polecenie odczytu jest blokowane do czasu wykonania innej instrukcji goroutine.
o Kanał z wartością zerową: Wartość zerowa kanału wynosi zero.
o Dla pętli kanału: Pętla for może przeglądać wartości wysyłane w kanale, aż do jej zamknięcia.
Składnia:
for item := range Chnl {
// statement(s)
}
Przykład:
// Program to illustrate how
// to use for loop in the channel
package main
import "fmt"
// the main function
func main() {
// Creating channel
// Using the make() function
mychnl := make(chan string)
// Anonymous goroutine
go func() {
mychnl <- "HFE"
mychnl <- "hfe"
mychnl <- "hello"
mychnl <- "Hellofromeveryone"
close(mychnl)
}()
// Using the for loop
for rest := range mychnl {
fmt.Println(rest)
}
}
o Długość kanału: Długość kanału można znaleźć w kanale za pomocą metody len(). W tym przypadku długość wskazuje liczbę wartości umieszczonych w kolejce w buforze kanału.
Przykład:
// Program to illustrate how to
// find the length of channel
package main
import "fmt"
// the main function
func main() {
// Creating channel
// Using the make() function
mychnl := make(chan string, 4)
mychnl <- "HFE"
mychnl <- "hfe"
mychnl <- "Hello"
mychnl <- "Hellofromeveryone"
// Finding length of the channel
// Using the len() function
fmt.Println("The Length of channel is: ",
len(mychnl))
}
o Przepustowość kanału: Funkcja cap() w kanale może być wykorzystana do określenia przepustowości kanału. Pojemność określa rozmiar bufora w tym przypadku.
Przykład:
// Program to illustrate
// how to find the capacity of the channel
package main
import "fmt"
// the main function
func main() {
// Creating channel
// Using the make() function
mychnl := make(chan string, 5)
mychnl <- "HFE"
mychnl <- "hfe"
mychnl <- "Geeks"
mychnl <- "Helloeveryone"
// Finding the capacity of channel
// Using the cap() function
fmt.Println("The Capacity of the channel is:
", cap(mychnl))
}
o Instrukcja Select i Case w kanale: Instrukcja select w Go jest podobna do instrukcji switch w tym, że nie przyjmuje żadnych parametrów wejściowych. Ta instrukcja pick jest używana w kanale do wykonania pojedynczej operacji z listy wielu operacji bloku sprawy.
KANAŁ JEDNOKIERUNKOWY
Jak wiemy, kanał jest mechanizmem komunikacji między jednocześnie wykonującymi się gorutynami, który umożliwia im wysyłanie i odbieranie danych od siebie nawzajem. Domyślnie kanał dwukierunkowy, ale możemy też zbudować kanał jednokierunkowy. Kanał jednokierunkowy może tylko odbierać dane lub taki, który może tylko wysyłać dane. Metodę make() można również wykorzystać do skonstruowania kanału jednokierunkowego, jak pokazano poniżej:
// Only to receive the data
c1:= make(<- chan bool)
// Only to send the data
c2:= make(chan<-bool)
Przykład:
// Program to illustrate concept
// of unidirectional channel
package main
import "fmt"
// the main function
func main() {
// Only for receiving
mychanl1 := make(<-chan string)
// Only for sending
mychanl2 := make(chan<- string)
// Display types of channels
fmt.Printf("%T", mychanl1)
fmt.Printf("\n%T", mychanl2)
}
Konwersja kanału dwukierunkowego na kanał jednokierunkowy
W Go możemy przekonwertować kanał dwukierunkowy na kanał jednokierunkowy lub innymi słowy kanał dwukierunkowy na kanał tylko do odbioru lub tylko do wysyłania, ale nie odwrotnie. Jest to pokazane w następującym programie:
Przykład:
// Program to illustrate how to
// convert bidirectional channel into
// the unidirectional channel
package main
import "fmt"
func sending(s chan<- string) {
s <- "Helloeveryone"
}
func main() {
// Creating bidirectional channel
mychanl := make(chan string)
// Here, sending() function convert
// bidirectional channel into send only channel
go sending(mychanl)
// Here, channel is sent
// only inside goroutine
// outside goroutine the
// channel is bidirectional
// So, it print Helloeveryone
fmt.Println(<-mychanl)
}
Użycie kanału jednokierunkowego: kanał jednokierunkowy jest używany do zapewnienia programowi bezpieczeństwa typu, co skutkuje mniejszą liczbą błędów. Możemy użyć kanału jednokierunkowego, gdy chcemy stworzyć kanał, który może tylko wysyłać lub odbierać dane. W tym rozdziale omówiliśmy programowanie współbieżne w Go, jak radzić sobie z problemami współbieżności w Go, jak utworzyć instrukcję Goroutine i select. Omówiliśmy również wiele Goroutines i kanał GoLang.
GoLang XII
Pakiety podstawowe
STRINGS
W pakiecie strings, Strings Go zawiera szeroką gamę funkcji do pracy z łańcuchami:
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(
// true
strings.Contains("rest", "es"),
// 2
strings.Count("rest", "r"),
// true
strings.HasPrefix("rest", "re"),
// true
strings.HasSuffix("rest", "st"),
// 1
strings.Index("rest", "e"),
// "x-y"
strings.Join([]string{"x","y"}, "-"),
// == "xxxxx"
strings.Repeat("x", 5),
// "yyxx"
strings.Replace("xxxx", "x", "y", 2),
// []string{"x","y","z","a","b"}
strings.Split("x-y-z-a-b", "-"),
// "rest"
strings.ToLower("REST"),
// "REST"
strings.ToUpper("rest"),
)
}
Czasami musimy pracować z łańcuchami jako danymi binarnymi. Aby przekonwertować ciąg na wycinek bajtów, wykonaj następujące czynności:
arr := []byte("rest")
str := string([]byte{'r','e','s','t'})
WEJŚCIE/WYJŚCIE (we/wy)
Pakiet io zawiera kilka funkcji, z których większość to interfejsy używane przez inne pakiety. Reader i Writer to dwa główne interfejsy. Czytelnicy pomagają w czytaniu przy użyciu metody Read. Pisarze pomagają pisarzom przy użyciu metody Write. Wiele funkcji Go przyjmuje jako argumenty Czytelników lub Pisarzy. Na przykład pakiet io zawiera funkcję Kopiuj, która przesyła dane z programu Reader do Writer:
func Copy(dst Writer, src Reader) (written int64, err error)
Struktury Buffer z pakietu bytes można użyć do odczytu lub zapisu do [] bajtu lub łańcucha znaków:
var buf bytes.Buffer
buf.Write([]byte("test"))
Bufor nie musi być inicjowany i może być używany z interfejsami Reader i Writer. Buf może użyć do przekonwertowania go na []bajt, wywołując bug.Bytes(). Możemy również użyć ciągów znaków, jeśli musimy odczytać z łańcucha. Metoda NewReader jest szybsza niż użycie bufora.
PLIKI I FOLDERY
Aby otworzyć plik, użyj funkcji Otwórz pakietu systemu operacyjnego. Przykład odczytania zawartości pliku i wyświetlenia jej na terminalu:
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("rest.txt")
if err != nil {
// handle error here
return
}
defer file.Close()
// get file size
stat, err := file.Stat()
if err != nil {
return
}
// read file
bs := make([]byte, stat.Size())
_, err = file.Read(bs)
if err != nil {
return
}
str := string(bs)
fmt.Println(str)
}
Używamy odroczonego pliku. Close() powinno zostać wywołane natychmiast po otwarciu pliku, aby upewnić się, że zostanie on zamknięty natychmiast po zakończeniu funkcji. Ponieważ czytanie plików jest tak powszechne, istnieje szybszy sposób, aby to osiągnąć:
package main
import (
"fmt"
"io/ioutil"
)
func main() {
bs, err := ioutil.ReadFile("rest.txt")
if err != nil {
return
}
str := string(bs)
fmt.Println(str)
}
Oto jak moglibyśmy przejść do tworzenia pliku:
package main
import (
"os"
)
func main() {
file, err := os.Create("rest.txt")
if err != nil {
// handle error here
return
}
defer file.Close()
file.WriteString("rest")
}
Aby pobrać zawartość katalogu, używamy tej samej metody os.Open, ale tym razem przekazujemy ścieżkę do katalogu, a nie nazwę pliku. Następnie wywoływana jest metoda Readdir:
package main
import (
"fmt"
"os"
)
func main() {
dir, err := os.Open(".")
if err != nil {
return
}
defer dir.Close()
fileInfos, err := dir.Readdir(-1)
if err != nil {
return
}
for _, fi := range fileInfos {
fmt.Println(fi.Name())
}
}
Często chcemy rekurencyjnie chodzić po folderze (przeczytać zawartość folderu, wszystkie podfoldery, wszystkie podfoldery,
). Aby w tym pomóc, pakiet path/filepath ma funkcję Walk:
package main
import (
"fmt"
"os"
"path/filepath"
)
func main() {
filepath.Walk(".", func(path string, info
os.FileInfo, err error) error {
fmt.Println(path)
return nil
})
}
Funkcja wywołuje każdy plik i folder w folderze głównym, który przekazujemy do Walk.
BŁĘDY
Go zawiera wbudowany typ dla wcześniej widzianych błędów (typ błędu). Korzystając z funkcji New w pakiecie błędów, możemy zbudować własne błędy:
package main
import "errors"
func main() {
err := errors.New("error-message")
}
POJEMNIKI I SORTOWANIE
Pakiet kontenerów Go zawiera wiele różnych kolekcji oprócz list i map. Jako przykład rozważmy pakiet kontenera/listy.
Lista
Pakiet list implementuje podwójnie połączoną listę. Połączona lista to forma struktury danych, która wygląda następująco:
Każdy węzeł na liście ma wartość (w tym przykładzie 1, 2 lub 3) i łącze do następnego węzła. Ponieważ jest to lista podwójnie połączona, każdy węzeł ma wskaźnik do węzła poprzedzającego. Ten program może wygenerować następującą listę:
package main
import ("fmt" ; "container/list")
func main() {
var y list.List
y.PushBack(1)
y.PushBack(2)
y.PushBack(3)
for c := y.Front(); c != nil; c=c.Next() {
fmt.Println(c.Value.(int))
}
}
Lista z wartością zero jest listą pustą (*List można również wygenerować za pomocą list.New). PushBack służy do dołączania wartości do listy. Zapętlamy listę, zaczynając od pierwszego elementu i podążając za wszystkimi połączeniami, aż osiągniemy zero.
SORTOWANIE
Sortowanie dowolnych danych jest obsługiwane przez pakiet sort. Istnieje wiele wbudowanych funkcji sortowania (dla wycinków typu int i float). Oto przykład, w jaki sposób możemy posortować nasze dane:
package main
import ("fmt" ; "sort")
type Person struct {
Name string
Age int
}
type ByName []Person
func (this ByName) Len() int {
return len(this)
}
func (this ByName) Less(x, y int) bool {
return this[x].Name < this[y].Name
}
func (this ByName) Swap(x, y int) {
this[x], this[y] = this[y], this[x]
}
func main() {
kids := []Person{
{"Thill",7},
{"Rach",11},
}
sort.Sort(ByName(kids))
fmt.Println(kids)
}
Funkcja sortowania wykonuje sortowanie. Jest połączony i sortowany. Ten rodzaj. Interfejs wymaga trzech metod: Len, Less i Swap. Tworzymy nowy typ (ByName), który odnosi się do wycinka tego, co chcemy posortować, aby zaprojektować własne sortowanie. Następnie definiuje się trzy techniki. Dlatego sortowanie naszej listy osób jest tak proste, jak rzutowanie listy na nasz nowy typ. Możemy również uporządkować według wieku, wykonując następujące czynności:
type ByAge []Person
func (this ByAge) Len() int {
return len(this)
}
func (this ByAge) Less(x, y int) bool {
return this[x].Age < this[y].Age
}
func (this ByAge) Swap(x, y int) {
this[x], this[y] = this[y], this[x]
}
HASZE I KRYPTOGRAFIA
Funkcja skrótu obniża zbiór danych do mniejszego stałego rozmiaru. Hashe są często używane w programowaniu do różnych celów, od wyszukiwania danych po proste identyfikowanie zmian. W Go funkcje skrótu są klasyfikowane jako kryptograficzne i niekryptograficzne. Niekryptograficzne funkcje skrótu obejmują adler32, crc32, crc64 i fnv, które można znaleźć w pakiecie hash. Oto przykład wykorzystujący crc32:
package main
import (
"fmt"
"hash/crc32"
)
func main() {
x := crc32.NewIEEE()
x.Write([]byte("rest"))
y := h.Sum32()
fmt.Println(y)
}
Ponieważ obiekt hash crc32 implementuje interfejs Writer, możemy zapisywać do niego bajty w taki sam sposób, jak każdy inny Writer. Po wpisaniu wszystkiego, czego potrzebujemy, wywołamy Sum32(), aby uzyskać uint32. Porównanie dwóch plików jest popularnym zastosowaniem crc32. Jeśli wartość Sum32 dla obu plików jest taka sama, jest bardzo prawdopodobne (ale nie pewne), że pliki są takie same. Jeśli wartości się różnią, pliki nie są takie same:
package main
import (
"fmt"
"hash/crc32"
"io/ioutil"
)
func getHash(filename string) (uint32, error) {
bs, err := ioutil.ReadFile(filename)
if err != nil {
return 0, err
}
x := crc32.NewIEEE()
x.Write(bs)
return x.Sum32(), nil
}
func main() {
x1, err := getHash("rest1.txt")
if err != nil {
return
}
x2, err := getHash("rest2.txt")
if err != nil {
return
}
fmt.Println(x1, x2, x1 == x2)
}
Kryptograficzne funkcje skrótu są porównywalne z niekryptograficznymi funkcjami skrótu, ale mają dodatkową właściwość polegającą na tym, że są trudne do odwrócenia. Ustalenie, kto stworzył kryptograficzny skrót zbioru danych, jest skomplikowane. Te skróty są często używane w aplikacjach zabezpieczających. SHA-1 to znana kryptograficzna funkcja skrótu. Oto jak jest używany:
package main
import (
"fmt"
"crypto/sha1"
)
func main() {
x:= sha1.New()
x.Write([]byte("rest"))
bs := x.Sum([]byte{})
fmt.Println(bs)
}
Ponieważ zarówno crc32, jak i sha1 implementują interfejs hash.Hash, ten przykład jest identyczny z crc32. Podstawowym rozróżnieniem jest to, że podczas gdy crc32 generuje 32-bitowy skrót, sha1 generuje 160-bitowy skrót. Ponieważ nie ma natywnego typu reprezentującego 160-bitową liczbę całkowitą, zamiast tego używamy wycinka 20-bajtowego.
SERWERY
Tworzenie serwerów sieciowych w Go jest stosunkowo proste. Zaczniemy od przyjrzenia się, jak utworzyć serwer TCP:
package main
import (
"encoding/gob"
"fmt"
"net"
)
func server() {
// listen on a port
l, err := net.Listen("tcp", ":9999")
if err != nil {
fmt.Println(err)
return
}
for {
// accept a connection
x, err := ln.Accept()
if err != nil {
fmt.Println(err)
continue
}
// handle the connection
go handleServerConnection(x)
}
}
func handleServerConnection(c net.Conn) {
// receive message
var msg string
err := gob.NewDecoder(c).Decode(&msg)
if err != nil {
fmt.Println(err)
} else {
fmt.Println("Receive", msg)
}
x.Close()
}
func client() {
// connect to the server
x, err := net.Dial("tcp", "127.0.0.1:9999")
if err != nil {
fmt.Println(err)
return
}
// send message
msg := "Hello Everyone"
fmt.Println("Sending", msg)
err = gob.NewEncoder(x).Encode(msg)
if err != nil {
fmt.Println(err)
}
x.Close()
}
func main() {
go server()
go client()
var input string
fmt.Scanln(&input)
}
W tym przykładzie wykorzystano pakiet encoding/gob, który ułatwia kodowanie wartości Go, aby inne programy Go (lub w tym przypadku ten sam program Go) mogły je odczytać. Dodatkowe kodowania można znaleźć w pakietach poniżej kodowania (takich jak encoding/json) oraz w pakietach innych firm.
http
Serwery HTTP są jeszcze prostsze w konfiguracji i obsłudze:
package main
import ("net/http" ; "io")
func helloo(res http.ResponseWriter, req *http.
Request) {
res.Header().Set(
"Content-Type",
"text/html",
)
io.WriteString(
res,
'< DOCTYPE html >
< html >
< head >
< title >Hello Everyone< /title >
< /head >
< body >
Hello Everyone!
< /body >
< /html >',
)
}
func main() {
http.HandleFunc("/helloo", helloo)
http.ListenAndServe(":9000", nil)
}
HandleFunc obsługuje trasę URL (/helloo) poprzez wywołanie danej funkcji. Możemy również użyć FileServer do obsługi plików statycznych:
http.Handle(
"/assets/",
http.StripPrefix(
"/assets/",
http.FileServer(http.Dir("assets")),
),
)
RPC
Pakiety net/rpc i net/rpc/jsonrpc ułatwiają udostępnianie metod do użycia w sieci (a nie w programie, który je wykonuje).
package main
import (
"fmt"
"net"
"net/rpc"
)
type Server struct {}
func (this *Server) Negate(i int64, reply *int64)
error {
*reply = -i
return nil
}
func server() {
rpc.Register(new(Server))
ln, err := net.Listen("tcp", ":9999")
if err != nil {
fmt.Println(err)
return
}
for {
x, err := ln.Accept()
if err != nil {
continue
}
go rpc.ServeConn(x)
}
}
func client() {
x, err := rpc.Dial("tcp", "127.0.0.1:9999")
if err != nil {
fmt.Println(err)
return
}
var result int64
err = x.Call("Server.Negate", int64(999), &result)
if err != nil {
fmt.Println(err)
} else {
fmt.Println("Server.Negate(999) =", result)
}
}
func main() {
go server()
go client()
var input string
fmt.Scanln(&input)
}
Ten program jest identyczny z przykładem TCP, z tą różnicą, że teraz utworzyliśmy obiekt do przechowywania wszystkich metod, które chcemy ujawnić, i wywołaliśmy metodę Negate z klienta.
ANALIZACJA ARGUMENTÓW WIERSZA POLECEŃ
Kiedy uruchamiamy polecenie z terminala, możemy podać mu argumenty. Widzieliśmy to za pomocą polecenia go:
go run mytestfile.go
Argumenty są uruchamiane i mytestfile.go. Możemy również przekazać flagi poleceń:
go run -v mytestfile.go
Możemy użyć pakietu flag do analizy argumentów i flag wysyłanych do naszego programu. Oto program, który generuje liczbę od 0 do 6. Możemy dostosować wartość maksymalną, wysyłając flagę do programu (-max=100):
package main
import ("fmt";"flag";"math/rand")
func main() {
// Define the flags
maxp := flag.Int("max", 6, "max value")
// Parse
flag.Parse()
// Generate a number between 0 and max
fmt.Println(rand.Intn(*maxp))
}
flag.Args() zwraca ciąg znaków [], jeśli istnieją dodatkowe argumenty inne niż flaga
PRYMITYWY SYNCHRONIZACJI
Pakiety sync i sync/atomic w Go umożliwiają bardziej typowe funkcje wielowątkowe.
Mutex
Mutex (wzajemna blokada na wyłączność) służy do ochrony współdzielonych zasobów przed nieatomowymi operacjami poprzez blokowanie bloku kodu do pojedynczego wątku na raz. Poniżej przedstawiono muteks:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
x := new(sync.Mutex)
for c := 0; c < 10; c++ {
go func(i int) {
x.Lock()
fmt.Println(c, "start")
time.Sleep(time.Second)
fmt.Println(c, "end")
x.Unlock()
}(i)
}
var input string
fmt.Scanln(&input)
}
Jeśli muteks (x) jest zablokowany, wszelkie dalsze próby jego zablokowania zakończą się niepowodzeniem, dopóki nie zostanie odblokowany. Należy zachować szczególną ostrożność podczas korzystania z muteksów lub prymitywów synchronizacji oferowanych przez pakiet sync/atomic. Tradycyjne programowanie wielowątkowe stanowi wyzwanie; błędy są proste do popełnienia. Problemy te są trudne do zidentyfikowania, ponieważ mogą zależeć od bardzo specyficznego, stosunkowo rzadkiego i trudnego do powielenia zestawu okoliczności. Jedną z głównych zalet Go jest to, że jego możliwości współbieżności są znacznie łatwiejsze do zrozumienia i zastosowania niż wątki i blokady.