Głównym problemem ujawniania informacji w sieci jest współdziałanie przeglądarek internetowych i serwerów WWW. Na najbardziej podstawowym poziomie sieci internauci żądają stron internetowych i innych obiektów, wpisując jednolity lokalizator zasobów (URL) w pasku adresu przeglądarki lub klikając łącze zawarte na stronie internetowej. Adres URL to globalny adres do dowolnego publicznie dostępnego dokumentu lub innego obiektu w sieci. Adres URL jest prostą, ale elegancką koncepcją, ponieważ umożliwia stronom internetowym i aplikacjom internetowym łatwe żądanie dowolnego obiektu w sieci. Na przykład adres URL logo Google to
http://www.google.com/intl/en_ALL/images/logo.gif.
Przeglądarki internetowe i serwery internetowe komunikują się za pomocą lingua franca sieci, protokołu HyperText Transfer Protocol (HTTP). (Zwróć uwagę na „http” w poprzednim adresie URL). HTTP definiuje reguły dotyczące żądań i otrzymywania treści internetowych. Rysunek 3-1 przedstawia podstawową interakcję, w której przeglądarka internetowa używa polecenia HTTP do zażądania podanego adresu URL.
Proste żądanie przeglądarki dotyczące strony internetowej generuje pojedyncze wejście dziennika
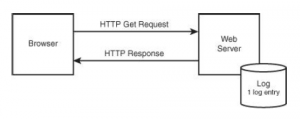
Jeśli wszystko pójdzie dobrze, serwer sieciowy odpowiada, wysyłając żądaną zawartość do przeglądarki internetowej, najprawdopodobniej strony internetowej w Hypertext Markup Language (HTML). Serwer sieciowy zwykle prowadzi dziennik wszystkich żądań adresów URL. W przypadku pojedynczego dokumentu HTML serwer WWW generuje pojedynczy wpis dziennika.
Prawdziwe strony internetowe prawie zawsze zawierają więcej treści niż pojedynczy dokument HTML, zwykle w postaci osadzonych obrazów i innych mediów. Po załadowaniu strony początkowej przeglądarka internetowa sprawdza kod HTML pod kątem tych adresów URL i pobiera dodatkowe obiekty bez żadnej interakcji z użytkownikiem. Rysunek 2 przedstawia ten bardziej realistyczny scenariusz, stronę internetową zawierającą obrazy.
Bardziej realistyczna strona internetowa zawiera osadzone multimedia, w wyniku czego wiele wpisów dziennika.
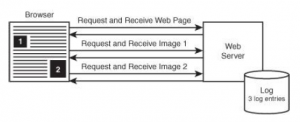
Przeglądarka pobiera oryginalną stronę HTML, a następnie pobiera dwa obrazy. Efektem końcowym są trzy żądania HTML, jedno dla strony HTML i jedno dla każdego obrazu. W takim przypadku docelowy serwer WWW tworzy trzy wpisy dziennika. Zwykle serwer WWW jest taki sam dla każdego z tych plików, ale nie musi tak być. Strona internetowa może zawierać multimedia z dowolnej liczby witryn osób trzecich
Media osadzone na stronie internetowej mogą pochodzić z dowolnego serwera WWW w Internecie, pozostawiając wpisy dziennika na wielu serwerach
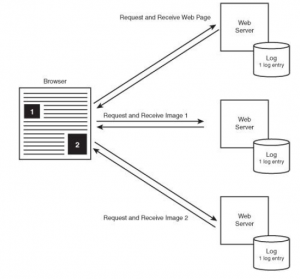
Reklamodawcy internetowi wykorzystują takie zachowanie polega na umieszczaniu reklam na stronach internetowych w internecie, które wskazują na serwer reklamodawcy. Główne strony HTML są pobierane z witryn, których odwiedzenia żąda użytkownik, ale przeglądarka użytkownika pobiera również reklamy z serwerów dużego reklamodawcy, umożliwiając reklamodawcy śledzenie aktywności użytkownika w dużych częściach sieci. Serwer sieciowy to stosunkowo prosta aplikacja; zawiera wiele dokumentów, takich jak strony internetowe, obrazy i inne treści, a także prywatny dziennik na komputerze dostępnym w Internecie. Wielu odwiedzających może przychodzić i wysyłać żądania HTTP dotyczące publicznie dostępnych dokumentów treści, ale kto ma dostęp do dziennika? Istnieją dwa podstawowe scenariusze. W pierwszym scenariuszu firma internetowa zarządza bezpośrednio serwerem WWW i kontroluje dzienniki. W wielu przypadkach webmaster sprawuje fizyczną kontrolę nad maszyną i nie ma uprzywilejowanego dostępu do zawartości serwera, w tym do jego dzienników.
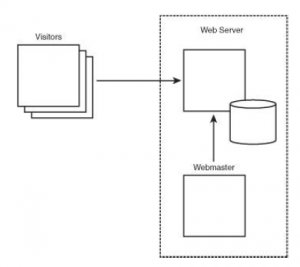
Przerywana linia na rysunku wskazuje granicę uprzywilejowanego dostępu do dzienników. Prywatny hosting ma miejsce w przypadku wielu średnich i dużych firm.
W drugim scenariuszu mniejsze firmy często płacą za hosting przez zewnętrzną usługę hostingową . Gdy serwer sieciowy obsługuje strona trzecia, należy ufać wielu dodatkowym osobom, które nie naruszą zabezpieczeń i ochrony prywatności serwera.
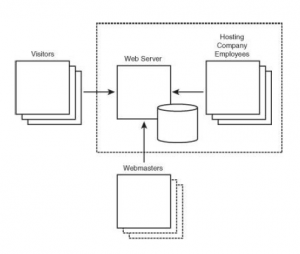
Bezpieczne zarządzanie serwerem internetowym e-commerce jest trudną propozycją, a ponieważ mniejsze firmy (i wiele dużych firm) mają ograniczone zasoby, często wydaje im się, że bardziej opłacalne jest outsourcing odpowiedzialności za hosting swojej obecności w sieci. Niestety, wprowadzenie firmy hostującej witrynę internetową udostępnia dziennik zarówno pierwotnej firmie internetowej, jak i pracownikom usługi hostingowej, tworząc kolejny potencjalny wektor ujawnienia. Co gorsza, najtańszą opcją hostingu jest zwykle hosting współdzielony, w którym wiele witryn internetowych znajduje się na tym samym serwerze fizycznym. Chociaż webmasterzy z tych innych witryn nie mają bezpośredniego dostępu do innych dzienników, mają uprzywilejowany dostęp do serwera współdzielonego i są w lepszej sytuacji niż osoba atakująca z zewnątrz, aby próbować uzyskać nieautoryzowany dostęp do dzienników innych hostowanych witryn. Efektem końcowym jest coraz większa grupa ludzi, którym należy ufać, że nie będą atakować ani niewłaściwie wykorzystywać poufnych danych dziennika. System nazw domen to kolejny komponent, który należy wziąć pod uwagę podczas badania wektorów ujawniania informacji związanych nawet z najbardziej podstawowym przeglądaniem stron internetowych. Protokół internetowy wymaga adresów IP do komunikacji z odległym serwerem. Dlatego gdy użytkownik wpisze adres URL, taki jak www.google.com, w pasku adresu przeglądarki, system operacyjny musi określić prawidłowy adres IP, którego ma użyć. Robi to za pomocą DNS. W tym przykładzie co najmniej dwa pakiety zawierają ruch DNS. Pierwsza, od użytkownika końcowego, zawiera zapytanie DNS żądające adresu IP www.google.com i jest wysyłana do lokalnego serwera nazw. Drugi pakiet to odpowiedź z lokalnego serwera nazw, która zawiera adres IP używany do komunikacji z www.google.com – w tym przypadku 64.233.169.99. Gdy komputer wysyłający żądanie otrzyma odpowiedź DNS, używa tego adresu IP przez pewien czas (często 24 godziny) i wysyła wówczas nowe żądanie. Kluczową ideą jest to, że aktywność DNS generuje kolejny ślad rekordów wskazujących miejsca docelowe surfowania po Internecie, poza bezpośrednim internautami i kanałem komunikacji firmy online. Należy jednak pamiętać, że żądania DNS obejmują tylko nazwy hostów, a nie adresy URL.